

"A chain is no stronger than its weakest link." - Anonymous
渲染管线的目的是要生成(generate)并渲染(render)一张2D图像(two-dimensional image)。其过程包括设置虚拟摄像机,光源信息,模型,位置,材质等等信息。整个渲染管线分为几个环节或者称为阶段(stage),分别完成不同的事情,每个环节生成的结果作为下一个环节的输入。
2.1 Architecture
实时渲染管线被分为四个阶段:
(应用)application ->(几何) geometry processing ->(光栅化)rasterization ->(像素)pixel processing
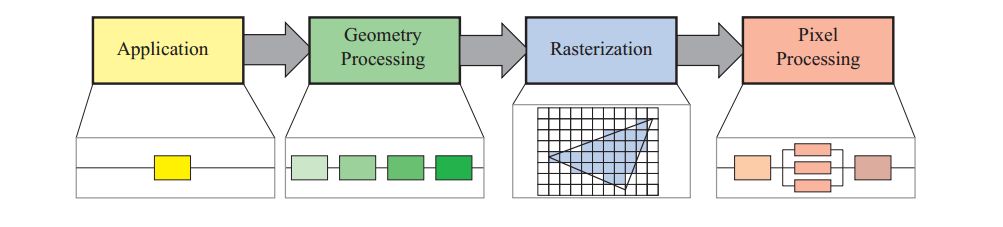
application阶段由应用程序本身控制,运行于CPU,执行碰撞检测,动画,物理模拟等过程,然后来到geometry processing执行坐标变换,投影等操作,决定了那些东西要怎样在哪里被渲染(what,how,where),运行于GPU;然后进入光栅化阶段,光栅化接收由三个顶点描述的三角形信息,然后找到所有这个三角形包含的像素信息,之后进入像素处理阶段;在像素处理阶段执行了一个针对每个像素的操作,决定了它的颜色,也可能会做深度测试看它是否可见,也可能blending一些新计算的颜色覆盖旧的颜色。光栅化和像素阶段都执行于GPU。
2.2 Application Stage
可以在应用阶段通过compute shader用GPU处理过程。在应用阶段结束后,传入几何阶段的,我们称为rendering primitives(图元),即点、线、三角。这个阶段并不分成更多的子阶段,为了提高效率,通常平行运算于多个CPU线程,这在CPU设计中通常被称为superscalar construction。在此阶段一般还会有碰撞检测,输入,优化算法等处理。
2.3 Geometry Processing
在GPU中对每个三角形和每个顶点做处理,分为如下几个函数过程:
Vertex Shading -> Projection -> Clipping -> Screen Mapping.

2.3.1 Vertex Shading
两个主要任务:处理顶点位置,处理其他程序员需要作为顶点信息输出的内容。
一般情况下可以存储顶点光照信息,这些信息之后会在三角形内部差值。随着现代GPU的不断升级,Shading的过程基本全部变成逐像素的,所以顶点shading的任务便更单一了,可能不会包含任何shading方程。
值得注意的是,第三版中单独把变换阶段独立出来,而在本版本中被包含到了Vertex Shading阶段。顶点从模型空间变换到世界空间,再变换到视图空间。顶点信息包含了位置,颜色,贴图坐标等,被一同输出到光栅化和像素阶段。视图变换后要进行投影变换和裁切,把结果变换到一个单位正方体内,称为canonical view volume。
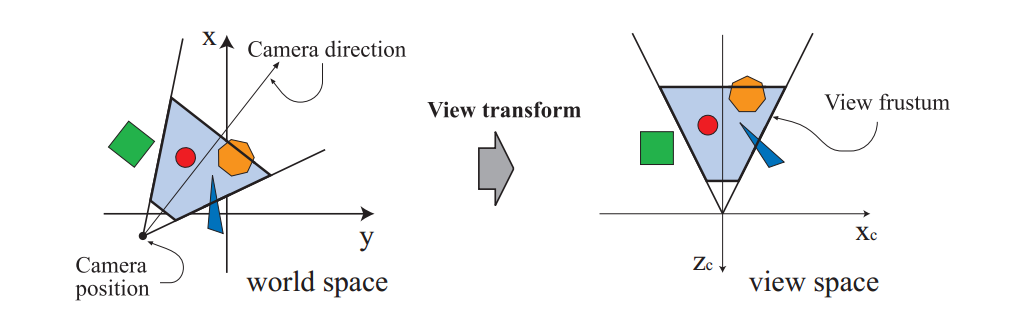
投影变换常用的两种:orthographic ,perspective;变换本身被描述为一个矩阵。点的z坐标信息并不存储于最终的图片信息中,而单独存储在z-buffer中。
2.3.2 Optional Vertex Processing
Vertex Shading结束后,有一些可选过程,例如:曲面细分(tessellation),几何着色(geometry shading)和流输出(stream output)。这些过程的使用取决于GPU是否支持以及程序员是否需要。他们之间彼此独立。
通过曲面细分,一个曲面可以被细分为多个三角形面,又不会占用过多的系统资源。曲面细分包括一些子过程:hull shader -> tessellator -> domain shader,把简单的点集转换成更大规模的点集,并可以通过摄像机远近控制。
几何着色的出现比曲面细分要早,所以有更多的GPU支持。和曲面细分比较像的是它也接收若干种类的图元输入然后产生新的顶点。但是它更简单,限制更多。例如烟火爆炸可以通过点表示每个火球,通过几何着色渲染为一个面向屏幕的片。
stream output可以让GPU变成一个几何引擎,我们可以把点的数据输出到数组供CPU或GPU在后面使用。例如生成粒子。
2.3.3 Clipping
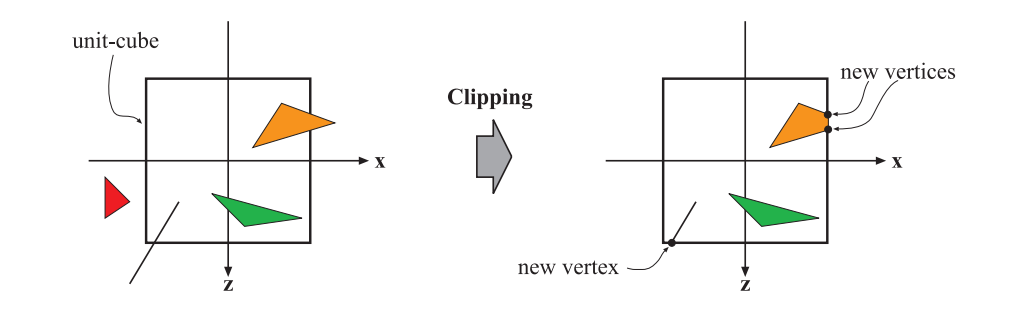
把在视野外的物体排除,视野边界上的进行裁切,然后再传入光栅化的过程。之所以在变换和投影后再进行裁切,是因为这样可以保证裁切问题的统一性。用户还可以在视锥裁切的6个平面外,自行增加裁切平面。
在裁切过程中使用4值齐次坐标,因为在透视空间内的三角形中,数值不会线性插值。最后执行透视除法(perspective division),使三角形的位置转换为三维空间的归一化设备坐标(normalized device coordinates)。然后把他们转换到屏幕坐标。
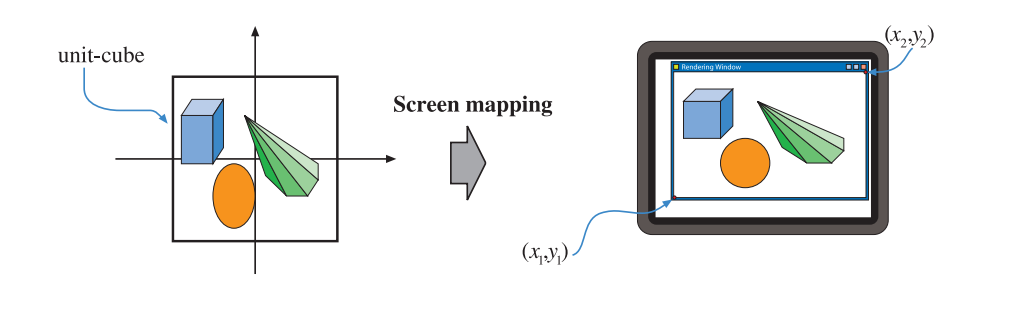
2.3.4 Screen Mapping
裁切后的图元被发送到屏幕映射阶段,坐标被映射到窗口坐标中,z坐标也同样被映射到$(0, 1)$。然后映射后的值被传入到光栅化阶段。
给定一行像素数组,应用笛卡尔坐标系,像素的最左侧为0.0,这在openGL和dx10以及以后的版本中广泛使用。像素的中间是0.5。d = floor(c), c = d + 0.5, d是整型index,c是像素的连续浮点值。但是上下边界的值对于opengl和directx略有不同。
2.4 Rasterization
两个子阶段:triangle setup,triangle traversal,光栅化也叫扫描转换(scan conversion),对每个像素给与颜色。

即从屏幕空间到屏幕上像素的转换。主要是一个像素是不是在一个图元的内部或一个三角形的内部,而标准一般是程序员制定,比如判断像素的中心点是否在三角形内部。还有诸如supersampling(SSAA)和multisampling(MSAA)的抗锯齿技术。
2.4.1 Triangle Setup
在这个阶段计算三角形的数据,固定功能的硬件用来做这个任务。
2.4.2 Triangle Traversal
在这个阶段,像素是否在三角形内部得到检测,然后一个片段(fragment)由像素和三角形重叠的部分生成。寻找哪个样本或像素在三角形内部通常称为三角形遍历(Triangle Traversal)。
2.5 Pixel Processing
两个子阶段:pixel shading,merging,逐像素操作在这里进行。
2.5.1 Pixel Shading
所有逐像素操作再此执行,以之后的shading数据作为输入。结果是若干颜色输出到下一阶段。此阶段由程序员书写的过程执行。有很多技术在此阶段得到应用,比如贴图。
2.5.2 Merging
每个像素的信息都被存储在color buffer中,它是一个矩形数组,每个颜色由r,g,b构成。这个阶段也叫ROP(raster operations(pipeline)/render output unit)。使上一阶段的fragment color与当前buffer中的值混合,通过比对z-buffer判断可见性。其他的通道或者缓存有:alpha channel(透明通道),stencil buffer(记录图元位置,8-bit per pixel)。这些在管线末执行的方法被称为ROP或者blend operations。
framebuffer表示所有系统中的buffer。双缓冲技术(double buffering)保证了当一帧渲染结束后再被替换到屏幕上。
2.6 Through the Pipeline
一个CAD的例子,贯穿始终。
Conclusion
这并不是唯一的pipeline,还有离线渲染环境中的micropolygon管线,以及后来取而代之的光线追踪(ray tracing)和路径追踪(path tracing)等。固定管线在本书中已经不再涉及。
Further Reading and Resources
- A Trip Down the Graphics Pipeline
- OpenGL Programming Guide (a.k.a. the "Red Book")