

"The display is the computer." - Jen-Hsun Huang
Photo by Nicola Gypsicola on Unsplash
前面介绍了一些GPU的历史背景,延迟是什么以及shader core是一个独立运行的小处理器。
3.1 Data-Parallel Architectures(并行数据结构)
不同的处理器在为了避免卡顿延迟方面有着不同的设计策略。CPU被设计成尽快的处理大量数据和大型代码库。除很少的一些SIMD向量处理器外,CPU的处理器单元处理时都是连续的。为避免延迟,大多CPU芯片都配有高速缓存。CPU也用分支预测(branch prediction),指令重整(instruction reordering),寄存器重命名(register renaming)和缓存预取(instruction reordering)来减少延迟。
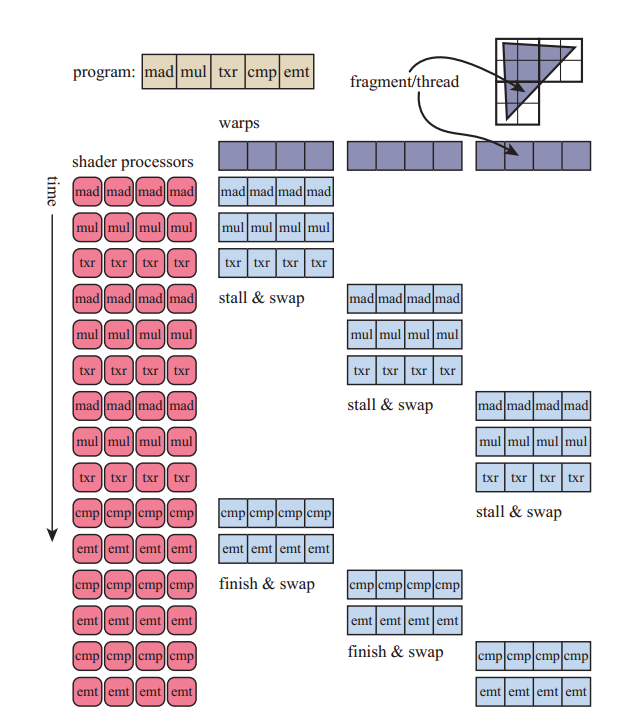
GPU由大量(上千)处理器构成,叫做shader cores。GPU是流处理器,大量相似数据大量平行的依次执行,这些调用彼此间独立,没有共享的可写入的内存。潜在的延迟(stall,或者说停滞)是,一个处理器可能需要等另一个处理器处理结束。
GPU被设计成大吞吐量的结构,由于每个处理器占用的面积小于CPU每个处理器占用的面积,所以相对的在处理更多逻辑和缓存操作的时候延迟更高。每个GPU线程(lane)不同于CPU线程(thread),携带了一些内存用来记录输入值等。用相同shader program的lane被编成组,NVIDIA称作warps, AMD称作wavefronts。
Occupancy:活动的warp数量与最大数量的比值。 GPU的硬件利用率,利用率越高不一定性能就越高,但如果利用率很小,性能肯定不会好。
另一个影响效率的因素:dynamic branching,条件语句或循环会导致线程分散(thread divergence),一些线程可能执行了条件或循环而另一些线程不用,那么这些不用执行的线程就要等待他们执行完。
3.2 GPU Pipeline Overview(GPU管线概览)
在这里讨论的是GPU的逻辑模型,也就是暴露给开发者的API。vertex shader 负责执行几何阶段的事情,完全可编程;tessellation阶段和geometry shader 都是可选的;裁切,三角形设置,三角形遍历被固定硬件执行;屏幕映射受窗口和viewport影响;合并阶段不可编程,但高度可配置,可以设置各种运算(处理了color, z-buffer, blend, stencil...);pixel shader和合并阶段一起于pixel processing stage执行。

3.3 The Programmable Shader Stage(可编程shader阶段)
vertex,pixel,geometry,tessellation shaders 共用一个统一的编程模型,内部他们有相同的指令集架构(instruction set architecture,ISA)。拥有这样统一模型的处理器在DirectX中称为common-shader core,拥有这种core的GPU称作其拥有统一shader架构。DirectX的HLSL和OpenGL的GLSL都可以编译为IL,供硬件识别。IL由驱动转换为ISA。
基础数据类型为32位单精度浮点数,在现代GPU中,32位整型和64位浮点数也被支持。
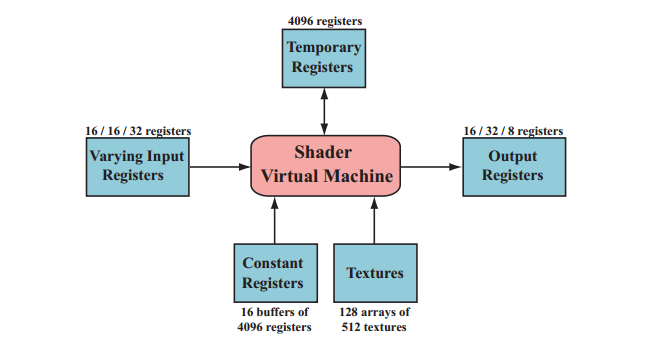
draw call 触发graphic API绘制图元,使图形处理管线开始工作并运行其shader程序。每个可编程shader阶段都接受两类参数,uniform inputs和varying inputs(常量和变量)。
常熟寄存器比给变量输入提供的寄存器要多得多。是因为每个顶点或像素的变量的输入和输出必须分开存储,存在一个上限,但是uniform输入存储一次会在整个draw call过程中使用。temporary register用来暂时存储。
flow control 指用分支指令改变代码执行的流向。shader支持两种flow control。Static flow control基于uniform输入,在draw call 过程中不会变化。主要好处是一个shader多处用。当所有调用都选取一个代码路径的时候,并不会发生线程发散;Dynamic flow control基于变量输入,意味着每个fragment可以执行不同的代码。但可能引起效率问题。
3.4 The Evolution of Programmable Shading and APIs(可编程Shading和API进化史)
(略)
3.5 The Vertex Shader(顶点着色器)
在此阶段前的处理,在DirectX中称为input assembler。
keywords:data representation,instancing
一个三角形mesh被一组点所描述,于每个点来说,还有一些其他可选属性如颜色和贴图坐标。也有顶点法线,不过从数学上讲,直接使用三角形的表面法线用于shading更合理。渲染中,三角面更多的用来代表曲面,顶点法线就用于表示表面的朝向。Vertex Shader一般情况下把顶点从模型空间转换到齐次裁剪空间,最少输出顶点的位置。Vertex Shader不能创建或删除顶点,也不能将结果传递给其他顶点。
一些顶点shader的例子:生成物体,变形;蒙皮技术;Procedural deformations,旗子,布料,水等;粒子生成;镜头扭曲,热浪,水波纹,翻页等通过framebuffer作为贴图使用在基于屏幕的网格中,使用procedural deformation;地形高度;

3.6 The Tessellation Stage(曲面细分阶段)
渲染曲面用,在DirectX11中开始,OpenGl4.0和OpenGL ES 3.2也支持。曲面的描述通常比用三角形描述更紧凑。
好处就是节省内存,节省CPU到GPU的传输。模型通常可以用表面描述转换为三角形网格网格然后再被随意变形,或让复杂的shading运算减少延迟。
三个元素:
DirectX:hull shader,tessellator,domain shader。
OpenGL: tessellation control shader,primitive generator,tessellation evaluation shader。
hull shader的输入是一个特殊的patch(比如Bézier patch ),包含一些控制点,描述了一个细分曲面。它有两个方法,第一个告诉tessellator多少个三角形要以什么样的配置生成;第二个在每个控制点上执行过程。hull shader也可以增删控制点(可选)。他的书厨师控制点和控制细分的数据,传递给domain shader。
tessellator由管线自动执行,用于给domain shader增加顶点。hull shader告诉tessellator需要什么样的细分面,如三角形,四边形(quadrilateral)或者等值线(isoline)。isoline是一组线段,有时候用于毛发的渲染。另一组由hull shader发送的值是tessellation factors(OpenGL中称为tessellation levels)。有两种类别:内边缘和外边缘。这两个内部因素决定三角形或多边形内细分发生的数量。外部因素决定每个边分裂的数量。通过允许单独控制,我们可以在细分中匹配相邻曲面的边,以便不受内部细分的影响。每个顶点被赋予重心坐标,用来标定每个点的相对位置。
hull shader总是输出一个patch和一组控制点。但是它可以通过向tessellator发送0或者更小(非数字或NaN)的外部曲面细分级别来丢弃patch。否则曲面细分器生成网格并传递给domain shader。每次调用domain shader时,都会使用来自hull shader的曲面控制点计算每个顶点的输出值。domain shader 和 vertex shader 有相似的数据流模式,输入一个来自tessellator的顶点,输出一个相应顶点。然后形成三角形传递到管线的下一个环节。
传递到hull shader 的patch通常改变很小或者没有改动。hull shader也可以用patch间的估计距离或屏幕大小来动态计算tessellation factors,如地形渲染。或者hull shader可以简单的为每个patch传递一组由应用程序计算提供的固定值。
tessellator执行一个固定的功能:生成顶点->给他们定位->指定他们生成的三角形或直线。数据的扩大环节被设计在shader之外以保证效率。
domain shader采用为每个点生成的重心坐标,在patch的evaluation equation中生成坐标,法线,贴图坐标和一些其他需要的顶点信息。
3.7 The Geometry Shader(几何着色器)
几何着色器可以把输入图元转换为其他图元,这是曲面细分阶段不能完成的。在DirectX10中于2006年末加入。需要Shader Model 4.0。同时OpenGL3.2和OpenGL ES 3.2也支持这种类型的shader。
输入是一个object和它关联的顶点。这个object通常由网格中的三角形,线段或点组成。被扩展的图元被几何着色器定义并处理。还可以传入三角形外的三个附加顶点,或邻近线段的两个顶点。如下图。
在DirectX11 Shader Model 5.0中,可以传入最多带有32个控制点的patch。这也就是说,曲面细分阶段生成patch更有效。
几何着色器被设计为处理输入数据或者制作有限数量的复制。比如生成6个变换后的数据拷贝用于模拟cube map。也可以用于高效生成高质量的级联阴影贴图(cascaded shadow maps)。再比如从点数据生成可变大小的粒子,沿着轮廓挤出鳍片用于毛发渲染,在阴影算法中找出物体边缘。
DirectX11增加了几何着色器使用instancing(实例化)的能力,也就是重复使用同一数据集变得更高效。在OpenGL4.0中是使用调用计数指定的。几何着色器也可以输出至多4个流(streams)。一个stream可以继续通过管线的其他阶段。所有流都可以被传给stream output render targets。
几何着色器确保输入输出的顺序相同,但这会影响性能,因为如果多个shader core平行运行,结果必须被存储和排序。
发出draw call 后,只有光栅化,曲面细分阶段和几何着色器这三个地方在GPU渲染管线中被生成。在这三个中,几何着色器的行为是最不可预测的,又考虑到这个阶段完全可编程,涉及资源和内存,又因为它没有很好的契合GPU的优势。所以通常较少使用。在一些移动设备中是使用软件实现的,所以在这种环境下不推荐使用。
3.7.1 Stream Output(流输出)
过去,数据通过渲染管线时获取不到中间结果。在Shader Model 4.0中引入了流的概念。顶点细分或者几何结束后都可以传递到流,然后一个额外的有序数组被传递到光栅化阶段。光栅化也可以完全关闭,渲染管线纯粹用作流处理器而不是处理图像。以这种方式处理的数据可以通过渲染管线发回,从而允许迭代处理。这种类型的处理在模拟流体或者粒子时十分有用。
流输出仅以浮点数的形式返回数据,因此它比较耗费内存。stream output 用于图元,而不是直接作用于顶点。如果网格沿管线发送,每个三角形生成它的3个输出顶点集合,以至于顶点的共享信息消失。为此,一般传递点的时候使用一个图元(点集)。
在OpenGL中stream output被称作transform feedback,是因为其大部分目标是把顶点变换然后进行更多处理。
3.8 The Pixel Shader(像素着色器)
这一阶段是可配置的,不可编程。对每个三角形遍历确认覆盖了哪些像素。光栅器也可以粗算每个像素被覆盖的程度。一个三角形中部分或完全重叠像素的部分称为片段(fragment)。
三角形顶点的值,包括z值,为每个像素跨三角形表面进行差值。这些值输入给pixel shader。在OpenGL中pixel shader被称作fragment shader。在本书中使用前者以保持一致性。点和线也会生成片段。
差值类型由pixel shader指定,通常我们使用透视校正差值(perspective-correct interpolation)。
在编程术语中,vertex shader的输出,三角形差值的结果等都高效的称为pixel shader的输入,在Shader Model 3.0后,fragment基于屏幕的坐标也成为一个扩展输入。还有作为flag标记的三角形面哪一面可见,在一个pass中渲染出三角形两个面不同材质时很重要。
一般情况下pixel shader 计算并输出片段的颜色,也可以产生透明度,修改深度值。在合并期间,这些值用来修改像素处的内容。模板缓冲(stencil buffer)通常不能修改,直接送到merge阶段。DirectX 11.3允许修改stencil。雾的计算和alpha测试在SM4.0从合并操作转变为pixel shader计算。
pixel shader可以遗弃输入放弃输出。例如Clip plane。
最初,pixel shader 只能输出到merge stage用于最终显示。随着时间推移,pixel shader可以执行的指令数大幅增加,使得MRT(Multiple Rendering Target)应运而生。不同于只把颜色和z-buffer作为结果发送,更多组值在每个片段被生成然后保存到不同的buffer中,每一个称作一个render target。render target具有相同的x,y维度,一些API可能支持不同尺寸。根据GPU render target的数量可能是4或者8个。
如单个渲染过程可以在一个目标中生成彩色图像,一个目标中生成目标标识符,在第三个中生成世界空间距离。这种能力也产生了一种不同类型的渲染管线,称作延迟着色(deferred shading),它让可见性和着色完成于单独的pass中。第一个pass存储每个像素位置和材质的数据,接下来的pass完成光照和其他effects。
pixel shader 的限制是不能读取相邻点的当前结果。用image processing可以解决这个问题。
一个例外,pixel shader 可以在计算梯度或者导数信息的时候间接的访问相邻点的片段信息。当一个pixel shader 访问梯度信息的时候,相邻fragment的差被返回。(这部分看得不是很明白,P51,第三段)
DirectX11引入了UAV(unordered access view),允许对任意位置的写入权限。在DirectX11.1中扩展到了除pixel shader 和 compute shader 的其他shader中。在OpenGL中称作(SSBO,shader storage buffer object)。像素着色器以任意顺序并行运行,此buffer在它们之间共享。
通常需要一些机制来避免race condition(data hazard),GPU用专门的atomic units(原子单位)来解决这个问题。shader在试图访问内存时会因为其他shader先stall。
在一般情况下,fragment的结果在merge阶段执行前被排序。DirectX11.3引入了ROVs(Rasterizer order views),强制执行顺序,和UAVs很像,shader可以以相同方式读写,区别在于ROV确保数据的执行顺序。ROV使像素着色器在不需要合并阶段的情况下,就可以编写自己的混合方法。不过如果检测到无序访问,pixel shader可能要stall一下。
3.9 The Merging Stage(合并阶段)
合并阶段将深度缓冲和颜色缓冲组合起来。对于不透明表面,用当前片段颜色替换之前保存的颜色,混合当前片段颜色和已存颜色的混合操作(Blending)常用于透明和合成。
为了避免合并时使之前的pixel计算白白浪费,很多GPU在像素着色器前执行合并测试。片段的深度z用于检测可见性,如果隐藏则直接被剔除,这称作early-z。pixel shader 可以改变片段的z值或直接丢弃片段。如果检测到pixel shader中有任意操作,则early-z通常被关闭或禁用,导致低效。DirectX 11和OpenGL 4.2允许像素着色器强制打开early-z测试。
合并阶段是固定功能阶段(三角形设置)和完全可编程阶段中间的地带。不可编程但高度可配置。颜色混合可以设置各种操作如颜色和alpha乘法,加减,最大值最小值以及按位逻辑操作。
DirectX10加入了可以用两个pixel shader和framebuffer 混合的能力,称为dual source-color blending(双原色混合),不能和MRT共同使用。MRT以另一种方式支持混合,在DirectX10.1中引入了在每个单独的buffer中使用不同混合操作的功能。
3.10 The Compute Shader(计算着色器)
GPU不仅可以用于实现传统渲染管线,也可用于诸如神经网络深度学习等的计算。由DirectX11引入,在渲染管线中没有固定位置的shader。由图形API调用,和顶点像素等其他shader一起使用。它使用和其他shader一样的处理器池,且可以访问输入输出缓冲区。warp和线程在compute shader中更明显。它还有线程组的概念,由1-1024个线程组成,由x, y, z坐标指定,便于在着色器代码中使用。每个线程组的线程都共享一部分内存,在DirectX11中,有32KB大小。compute shader由线程组执行,以确保所有线程同时执行。
compute shader 的一个重要的优势是它可以访问GPU上生成的数据,由GPU向CPU发送数据会导致延迟。Post-processing是一种Compute shader的常见用法。compute shader也同样适用于:粒子系统,网格处理如面部动画(facial animation),culling(剔除),图像过滤(image filtering),改进深度精度,阴影,景深(depth of field)以及任何可以用GPU执行的任务,等等。
Further Reading and Resources
- Giesen’s tour of the graphics pipeline
- OpenGL Superbible
- OpenGL Programming Guide