

"All it takes is for the rendered image to look right." — Jim Blinn
在计算机图形学中,纹理化是一个过程,它使用一些图像,函数或其他数据源,选取一个表面,并在每个位置修改其外观。例如在一个由两个三角形组成的矩形上,贴上砖块图样的贴图,使得矩形看起来像砖墙的外观。
然而,由于缺乏几何形状,贴上纹理的砖墙并不令人信服。如,砂浆应该是无光泽的,砖是有光泽的。可以使用粗糙度贴图来表示这些信息,作为第二张贴图使用在表面上。
观察者现在会看到有光泽的砖和没有光泽的砂浆,但每个砖面都是平坦的。通过使用凹凸贴图可以改变砖的法线,似的他们在渲染时看起来起伏。
但砖块应该在砂浆上投下阴影,且在砂浆上面伸出来,在视野中遮挡后面。视差贴图能够通过修改模型三角的高度来取代表面。
6.1 The Texturing Pipeline(贴图管线)
贴图是一种有效的改变表面材质或者模型本身的技术。可以通过单一像素考虑贴图的作用。着色的计算时吧材质颜色和光照以及其他因素一起考虑的结果。纹理通过修改着色方程中的值来改变着色结果。这些值通常基于表面上的位置。对于砖墙的例子,表面上的点被对应替换为贴图颜色。贴图纹理中的像素通常被称为纹素(texel,用来与屏幕像素pixel区分)。
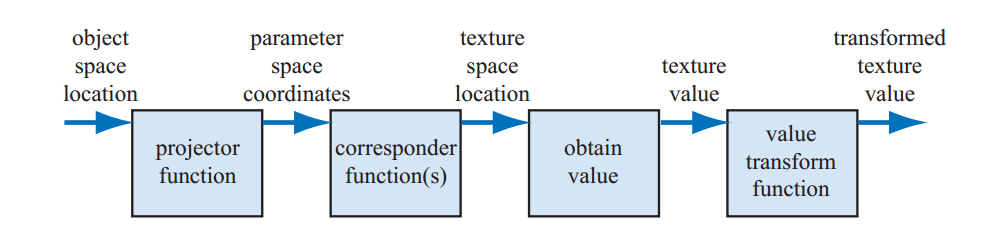
贴图的过程可以用流水线来描述。
空间中的位置是贴图过程的起点,这个位置可以在世界空间中,但更常见于模型空间。当模型移动时,贴图随之移动。使用Kershaw的话说,之后一个投影函数应用于空间中该点,产生一系列称作纹理坐标(texture coordinates)的值,用于访问纹理。这个过程称作mapping(映射)。
在使用这些值访问纹理之前,会有一个或者若干映射函数(corresponder function)用于把贴图坐标转换到纹理空间(texture space)。这些纹理空间用于从纹理获取值。如它们可能是数组的index从纹理中返回一个像素。然后,可以通过value transform function对检索到的值进行转换,然后使用转换后的值修改表面的属性,如材质或者法线。下图展示了单个纹理在应用时执行的过程,管线之所以复杂是因为每个步骤都要为用户提供相应的控制,并非所有步骤都需要始终激活:
使用这个管线,当三角形使用了砖墙贴图,表面生成了一个样本:
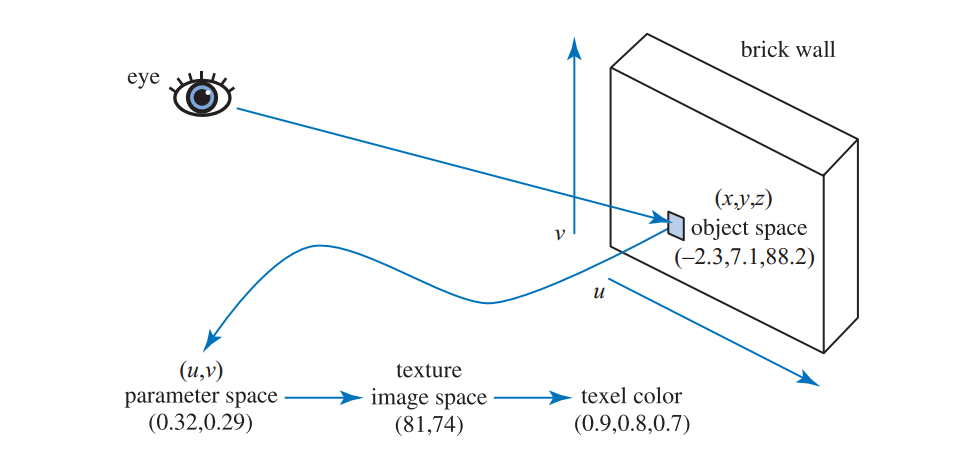
首先找到$(x,y,z)$坐标,在这里是$(-2.3,7.1,88.2)$。然后对该位置应用投影函数,使坐标转换到二维空间,parameter space(也就是uv空间)。这里的投影函数相当于正交投影,就像将砖墙图像照射到三角形表面的投影仪。转换后的结果是0到1的值对。这里是$(0.32,0.29)$。纹理坐标用于查找图像在此位置的颜色。在本例中,砖纹理的分辨率是256×256,所以用$(u,v)\times256=(91.92,74.24)$,丢弃小数部分,查找到砖纹理中对应$(81,74)$的点的颜色为$(0.9,0.8,0.7)$。纹理颜色属于sRGB颜色空间,因此如果要在着色器方程中使用该颜色,需要转换为线性空间,得出$(0.787,0.604,0.448)$。
6.1.1 The Projector Function(投影函数)
纹理过程的第一步是获取表面位置投影到uv空间。通常,建模软件可以允许艺术家对每个顶点定义uv坐标。这通常是通过投影函数(projector function)或网格展开算法(mesh unwrapping algorithms)实现的。建模程序中常用的函数包括球面,柱面和平面投影。
其他输入可用于投影功能。如,表面法线可用于选择六个平面投影方向用于平面。匹配纹理的问题常出现在接缝处。Geiss讨论了一种混合它们使用的技术。Tarini等提出了polycube maps,一个模型映射到多个cube projection上面。
其他projector functions根本就不是投影,而是作为表面创建和曲面细分的隐含部分。例如,参数化曲面具有一组作为定义自然存在的uv。纹理坐标也可以由各种不同类型的参数生成,如视图方向,表面温度等等。投影函数的目标是生成纹理坐标,基于位置的函数只是一种方法。
非交互式渲染器通常将这些投影函数称为渲染过程的一部分。单个投影函数有可能足以满足整个模型,但有时需要细分模型应用各种类型的投影:
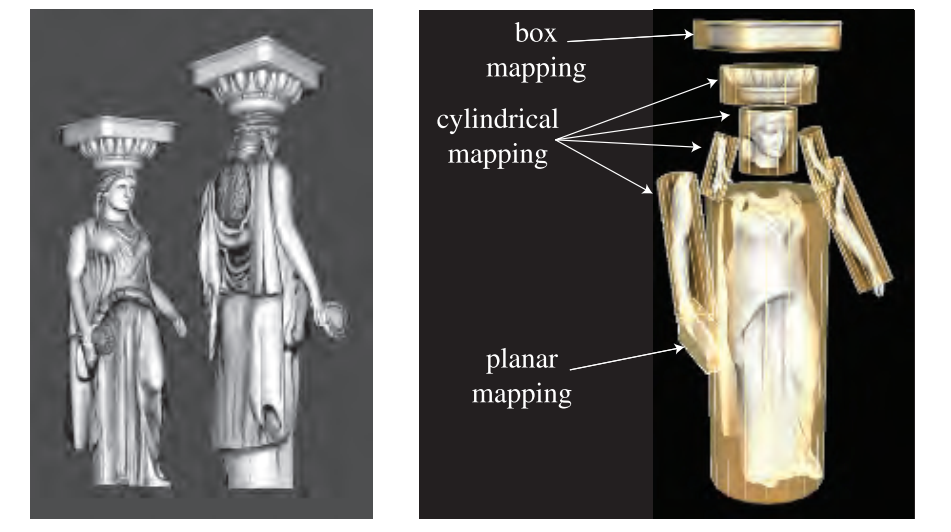
在实时渲染中,projector functions 常用于建模阶段,投影的结果存储在顶点中。不过有时在vertex shader或者pixel shader中应用投影函数是有好处的。这样可以提高精度,并有助于实现各种效果,动画。有些方法拥有自己专用的projector functions,如环境贴图。
- 球形投影将点投射到以某个点为中心的假想球体上,此投影与Blinn和Newell的环境映射方案相同。
- 圆柱投影的u方向纹理坐标与球面投影相同,v方向沿着圆柱轴向。对具有自然轴的物体如旋转表面很有用。当曲面几乎垂直于圆柱轴时会发生扭曲。
- 平面投影沿着一个方向平行投射。它使用正交投影。应用贴花时很有用。
对于平面上的扭曲,艺术家需要手动拆分模型为接近的形状。有一些工具使用unwrapping减少这种扭曲,或生成一组接近最佳的平面投影,等等,以辅助这一过程。目标是为每个多边形赋予更均匀的纹理区域,同事保持更多的网格链接。连接性很重要,因为分离的边缘会在采样时产生失真。unwarapping 的过程是一个非常重要的研究方向,称为mesh parameterization,下图展示了上图的uv展开效果:

纹理坐标有时是一个三维体积。在这种情况下,纹理坐标表示为$(u,v,w)$,其中w是沿投影方向的深度。还有些系统使用四个坐标,指定为$(s,t,r,q)$,q用作齐次坐标中的第四个值。它的作用类似于电影或者幻灯片投影机,投影纹理的大小随着距离而增加。例如,投射一个带图案的(使用图案遮光罩的)聚光灯到舞台或者表面上。
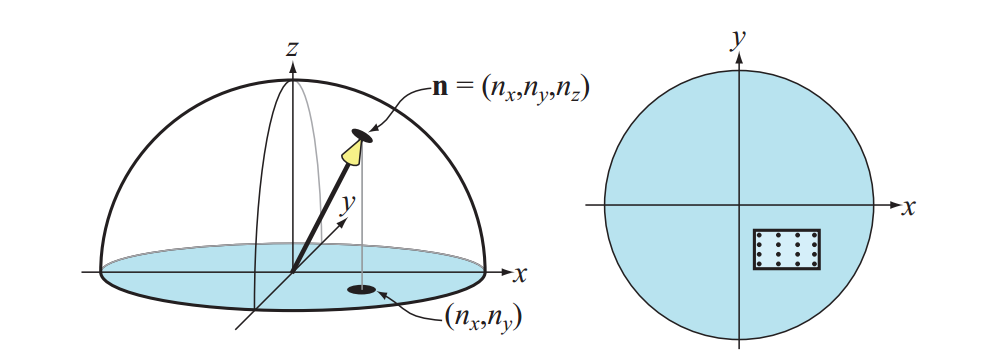
另一种重要的纹理坐标空间类型是方向性的,其中空间中的每个点都由一个输入的方向向量访问。这种空间的可视化的一种方法是使用在单位球面上的点,每个点处的法线表示用于访问该位置的纹理方向。使用方向参数化的最常见的纹理类型是立方体贴图。
还有就是一维纹理图像也是有用的。比如地形模型上,着色可以通过高度来决定,例如,低的地方是绿色,高的山峰是白色。线条也可以贴图,如渲染雨的时候,使用很多带透明度的贴过图的长线。还有转换值的时候,可以把一维纹理作为查找表。
由于可以将多个纹理应用于表面,因此可能需要定义多组纹理坐标。这些纹理坐标在表面上插值用于检索纹理,然而在插值之前,这些纹理坐标由映射函数(corresponder function)变换。
6.1.2 The Corresponder Function(映射函数)
映射函数(corresponder function)将纹理坐标转换为纹理空间位置。它们可以灵活地将纹理应用于表面。映射函数的一个例子是使用API来选择纹理的一部分进行显示;只有这部分图像用于后续操作。
另一种类型的映射函数是矩阵变换,其可以应用于顶点或像素着色器。 这使得能够在表面上让纹理平移,旋转,缩放,剪切或投射。令人惊讶的是,纹理变换的顺序与人们期望的顺序相反。 这是因为纹理变换实际上会影响确定图像所在位置的空间变换。图像本身不是被转换的对象,定义图像位置的空间改变了。
另一类映射函数能控制图像的应用方式。我们知道uv在[0, 1]范围。 但是在这个范围之外会发生什么?这由映射函数确定。 在OpenGL中,这种类型的映射函数称为“wrap模式”(wrapping mode),在DirectX中,它被称为“纹理寻址模式”(texture addressing mode)。这种类型的常见映射函数有:
- wrap(DirectX),repeat(OpenGL)或tile:图像在表面重复;在算法上,纹理坐标的整数部分被删除。常为默认设置。
- mirror:图像在表面重复,但是每次重复一次要翻转一次。正常反转正常...
- clamp或者clamp to edge:重复纹理边缘。当双线性插值发生在纹理边缘附近时,可以避免纹理发生意外的取样。
- border(DirectX)或clamp to border(OpenGL):纹理坐标在[0, 1]使用单独定义的边框颜色进行渲染。可以很好地将贴花渲染到单色表面上,例如,因为纹理边缘将与边框颜色平滑地融合。

在DirectX中,还有一个镜像一次模式,它沿着纹理坐标的0值镜像纹理一次,然后clamp。对于对称贴花很有用。
重复平铺纹理可以像场景中添加更多的视觉细节,但是重复多次后眼睛会识别出重复图案。避免这种问题的常见方法是将纹理与非平铺的纹理组合。这种方法可以扩展,如Andersson 描述的商业地形渲染系统。 在该系统中,基于地形类型,高度,坡度和其他因素组合多个纹理。纹理图像也与几何模型(例如灌木和岩石)放置在场景中的位置相关联。
避免周期性的另一个选择是使用着色器程序来实现随机重组纹理图案的专用映射函数。 Wang tiles就是这种方法的一个例子。Wang tiles set是一组可以匹配边缘的方形tile。 在纹理化过程中随机选择tile。Lefebvre和Neyret提出了一个类似的映射函数,使用dependent texture reads和表格避免图案重复。
6.1.3 Texture Values(纹理值)
在使用映射函数产生纹理空间坐标后,坐标用于获得纹理值。 对于图像纹理,这是通过访问纹理从图像中检索纹理元素信息来完成的。 图像纹理构成了实时工作中绝大部分的纹理使用,但也可以使用程序纹理(procedural texture)。 在程序纹理的情况下,从纹理空间位置获得纹理值的过程不涉及存储器查找,而是涉及函数的计算。
从纹理中拿到的值可以先被变换再进行使用。可以在shader中执行这些变换。一个常见的示例是将数据从无符号范围$(0, 1)$映射到$(-1.0,1.0)$,用于对存储在颜色贴图中的法线进行着色。
6.2 Image Texturing(图像贴图)
在本节中,我们特别关注快速采样和过滤纹理图像的方法。5.4.2节讨论了锯齿问题,特别是在渲染对象边缘方面。 纹理也可能存在采样问题,但它们出现在正在渲染的三角形的内部。
使用例如texture2D传入坐标值来访问纹理。GPU负责将uv转换到纹素坐标。不同API中的纹理坐标系有两个差异。DirectX的左上角是$(0,0)$,右下角是$(1,1)$。顶行是文件中的第一行。在OpenGL中,纹素$(0,0)$位于左下方,y轴和DirectX相反。纹素有整数坐标,但我们经常想要访问纹素之间的位置并在它们之间进行混合。这提出了像素中心的浮坐标是什么的问题。 Heckbert 讨论了如何使用两个系统:截断(truncating)和舍入(rounding)。DirectX 9将每个中心定义为$(0,0)$,它使用rounding。这个系统有些令人困惑,因为左上角像素的左上角,在DirectX的原点,值为$(0.5,0.5)$。DirectX 10更改为了和OpenGL系统一样,其中纹素的中心具有小数值$(0.5,0.5)$:truncating,或更准确地说,flooring,其中小数被丢弃。flooring是一个更自然的系统,可以很好地映射到语言,如在像素$(5,9)$中,为u坐标定义了5.0到6.0的范围,为v坐标定义了9.0到10.0的范围。
有个值得解释的术语dependent texture read,它有两个定义。第一种尤其适用于移动设备:当通过类似texture2D访问纹理时,只要像素shader计算纹理坐标而不是使用从顶点着色器传入的未修改的坐标,就会触发dependent texture read。注意,这包括对输入纹理坐标的任何更改,甚至是交换uv这样的简单操作。在那些不支持OpenGL ES 3.0的较旧的移动GPU上,当着色器没有执行dependent texture read时,有更高的运行效率,因为纹素数据接下来可以被预取(prefatch)。对于早期的桌面GPU,这个术语的另一个较旧的定义尤为重要。在这里,当一个纹理的坐标取决于某些先前纹理值的结果时,触发dependent texture read。例如,一个纹理可能会更改着色法线,这反过来会更改用于访问cube map的坐标。早期GPU上的此类功能有限甚至不存在。今天,这些reads可能会对性能产生影响,具体取决于批量计算的像素数量以及其他因素。(具体参照23.8节)
GPU中使用的纹理图像大小通常为$2^m×2^n$个纹素,其中m和n是非负整数。 这些被称为二次幂(power-of-two ,POT)纹理。 现代GPU可以处理任意大小的非二次幂(non-power-of-two , NPOT)纹理,这允许将生成的图像视为纹理。 但是,一些较旧的移动GPU可能不支持对NPOT纹理的mipmapping操作(第6.2.2节)。 图形加速器对纹理大小有不同的上限。 如,DirectX 12最多允许$16384^2$的纹素。
假设我们有一个256×256纹素大小的纹理,我们希望将它用作一个正方形的纹理。只要屏幕上的投影方块大小与纹理大致相同,方块上的纹理看起来几乎就像原始图像一样。但是如果投影的方块覆盖了原始图像所包含的十倍像素(称为放大,magnification),或者如果投影的方块仅覆盖屏幕的一小部分(缩小,minification),会发生什么?答案是,它取决于您决定使用哪种采样和过滤方法来处理这两种不同的情况。
本章讨论的图像采样和过滤方法适用于从每个纹理读取的值。 然而,期望的结果是防止最终渲染图像中的混叠,理论上需要对最终像素颜色进行采样和滤波。 这里的区别在于将输入过滤到着色方程或过滤其输出。 只要输入和输出是线性相关的(对于诸如颜色的输入都是如此),则过滤单个纹理值等同于过滤最终颜色。但是,存储在纹理中的许多着色器输入值(例如曲面法线和粗糙度值)与输出具有非线性关系。标准纹理过滤方法可能无法很好地处理这些纹理,从而导致锯齿。 第9.13节讨论了过滤此类纹理的改进方法。
6.2.1 Magnification(放大)

一个尺寸为48×48纹素的纹理在贴在正方形上,贴图尺寸太小,底层图形系统必须将它放大处理。最常用的放大滤波技术是最近邻(nearest neighbor,实际使用的滤波器是box filter)和双线性插值(bilinear interpolation)。 还有立方卷积(cubic convolution),它使用4×4或5×5像素阵列的加权和。可以实现更高质量的放大。尽管目前通常不能获得对立方卷积(也称为双三次插值,bicubic interpolation)的本机硬件支持,但它可以在着色器程序中执行。
上图左侧使用的是最邻近方法。这种放大技术的特征是各个纹素可能变得明显。这种效应称为像素化(pixelation ),因为该方法在放大时从离每个像素中心最近的纹理像素值取,导致块状外观。 虽然这种方法的质量有时很差,但每个像素只需要获取一个纹素。
在该图的中间图像中,使用双线性插值(有时称为线性插值)。对于每个像素,这种滤波找到四个相邻纹素并在二维中线性插值以找到该像素的混合值。结果是模糊的,使用最近邻法的大部分锯齿都消失了。 作为实验,尝试在眯眼时查看左图,因为这与低通滤波器具有大致相同的效果,并且可以更多地显示脸部。
回到砖纹理示例,我们不丢弃小数部分,得到$(p_u,p_v)=(81.92,74.24)$。使用OpenGL的左下原点纹素坐标系,因为它匹配标准的笛卡尔坐标系。我们的目标是在四个最接近的纹素之间进行插值,使用其纹理像素中心定义一个纹理像素有大小的坐标系。为了找到最近的四个像素,我们从样本位置减去像素中心坐标$(0.5,0.5)$,给出$(81.92,74.24)$。 丢弃分数,四个最接近的像素范围从$(x,y)=(81,73)$到$(x + 1, y + 1)=(82,74)$。 对于我们的例子,小数部分$(0.42,0.74)$是样本相对于由四个纹素中心形成的坐标系的位置。 我们将此位置表示为$(u', v')$。
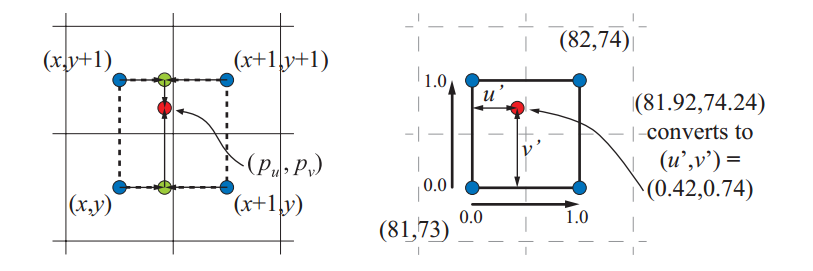
将纹理访问函数定义为$t(x,y)$,其中x和y是整数,并返回纹素的颜色。任何位置$(u',v')$的双线性插值颜色可以计算为两步过程。首先,底部纹素$t(x,y)$和$t(x+1,y)$水平插值(使用u'),类似地,对于最顶部的两个纹素,$t(x,y+1)$和$t(x+1,y+1)$。对于底部纹素,我们得到$(1-u')t(x,y)+u't(x+1,y)$(图中底部绿色圆),对于顶部,$(1-u')t(x,y+1)+u't(x+1,y+1)$(图中顶部绿色圆)。 然后垂直插入这两个值(使用v'),则$(p_u,p_v)$处的双线性插值颜色$\boldsymbol{b}$是
$$
\begin{align}
\boldsymbol{b}(p_u,p_v)=&(1-v')((1-u')\boldsymbol{t}(x,y)+u'\boldsymbol{t}(x+1,y))\\
&+v'((1-u')\boldsymbol{t}(x,y+1)+u'\boldsymbol{t}(x+1,y+1))\\
=&(1-u')(1-v')\boldsymbol{t}(x,y)+u'(1-v')\boldsymbol{t}(x+1,y)\\
&+(1-u')v'\boldsymbol{t}(x,y+1)+u'v'\boldsymbol{t}(x+1,y+1)
\end{align}\tag{6.1}
$$
直观地说,靠近我们样本位置的纹素将更多地影响其最终值。这确实是我们在这个等式中看到的。 右上角纹素$(x+1,y+1)$具有$u'v'$的影响。注意对称性:右上角的影响等于左下角和样本点形成的矩形区域。 回到我们的例子,这意味着从这个纹素中检索的值将乘以$0.42\times0.74$,$0.3108$。 从该纹素顺时针方向看,其他乘数为$0.42\times0.26$,$0.5\times0.26$和$0.58\times0.74$,这些权重的所有四个总和为1.0。
伴随放大会造成模糊,常见解决方案是使用细节纹理。 这些纹理代表精细的表面细节,从手机上的划痕到地形上的灌木丛。 这种细节作为单独的纹理覆盖在放大的纹理上,以不同的比例。 细节纹理的高频重复图案与低分辨率放大的纹理相结合,具有类似于使用单个高分辨率纹理的视觉效果。
双线性插值在两个方向上线性插值。 但是,不需要线性插值。 假设纹理由棋盘图案中的黑白像素组成。 使用双线性插值可在纹理上提供不同的灰度样本。 通过重新映射使得,例如,所有低于0.4的灰色都是黑色,所有高于0.6的灰色都是白色,而中间的灰色被拉伸以填充间隙,纹理看起来更像棋盘,同时也给出了纹素之间的一些过度:

使用更高分辨率的纹理会产生类似的效果。例如,假设每个棋盘方格由4×4纹素组成,而不是1×1。围绕每个棋盘的中心,插值颜色将是完全黑色或白色。
在图6.8的右侧,使用了双三次滤波器,并且很大程度上消除了剩余的块效应。 应该注意的是,双三次滤波器比双线性滤波器更昂贵。 但是,许多高阶滤波器可以表示为重复线性插值(另见第17.1.1节)。 因此,纹理单元中用于线性插值的GPU硬件可以通过多次查找来利用。
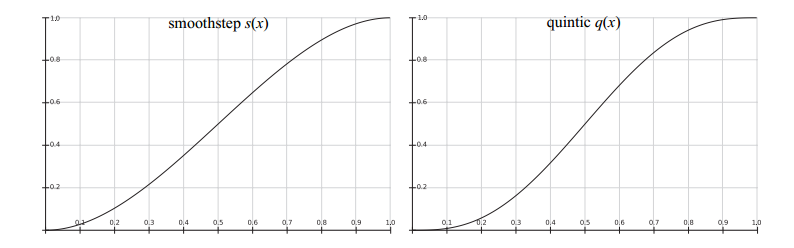
如果认为双立方滤波器太昂贵,Quílez提出了一种使用平滑曲线在一组2×2纹素之间进行插值的简单技术。 我们首先描述曲线然后描述技术。两条常用曲线是平滑曲线和五次曲线:
$$
\underbrace{s(x)=x^2(3-2x)}_{smoothstep}\quad and \quad \underbrace{q(x)=x^3(6x^2-15x+10)}_{quintic}\tag{6.2}
$$
这些对于您希望从一个值平滑插值到另一个值的许多情况非常有用。 smoothstep曲线具有$s'(0)=s'(1)=0$的特性,并且在0和1之间平滑。五次曲线具有相同的属性,但$q''(0)= q''(1)= 0$, 即,二阶导数在曲线的开始和结束处也是0:
该技术首先计算,首先将样本乘以纹理维度并加0.5。保留整数部分以供稍后使用,并将分数存储在u'和v'中,其范围为[0, 1]。 然后将$(u',v')$变换为$(t_u,t_v)=(q(u'),q(v'))$,仍然属于$[0,1]$。最后,减去0.5并重新加入整数部分;然后将得到的u坐标除以纹理宽度,并且类似地处理v。此时,新纹理坐标与GPU提供的双线性插值查找一起使用。 请注意,此方法将在每个纹素处给出平稳,这意味着如果纹素位于RGB空间中的平面上,那么这种类型的插值将提供平滑但仍然是阶梯状的外观,但可能并非总是期望这样。
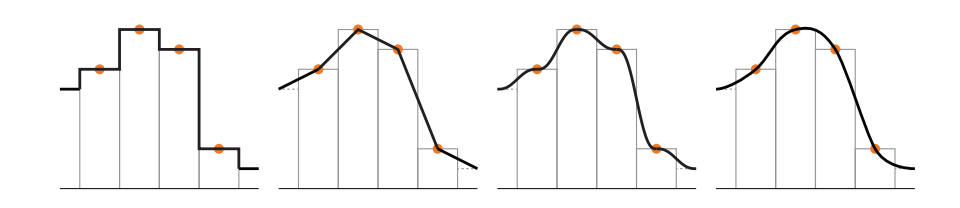
上图表示放大一维纹理的四种不同方法。 橙色圆圈表示纹素的中心以及纹素值(高度)。 从左到右依次为:最近邻,线性,使用每对相邻纹素之间的五次曲线,以及使用三次插值。
6.2.2 Minification(缩小)
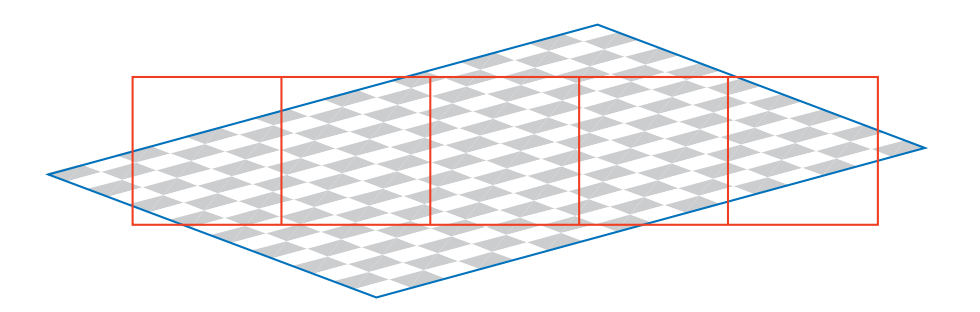
当纹理最小化时,几个纹素可能会覆盖像素的单元格,如图所示。 要为每个像素获取正确的颜色值,应该集成影响像素的纹素的效果。 然而,很难准确地确定特定像素附近的所有纹素的确切影响,并且实际上不可能实时地完成。(每个像素单元包含多个棋盘格)
由于这种限制,GPU上使用了几种不同的方法。一种方法是使用nearest neighbor,和相应的放大滤波器完全相同,即,它选择在像素单元的中心可见的纹素。此过滤器可能会导致严重的失真问题。接近地平线的地方出现失真,因为只有影响像素的许多纹素中的一个被选择来表示表面。当表面相对于观察者移动时,这种伪影甚至更明显,并且是所谓的temporal aliasing的一种表现。
另一种通常可用的滤波器是双线性插值,还是与放大滤波器完全一样。 此过滤器仅略微优于nearest neighbor的缩小方法。 它混合了四个纹素而不是仅使用一个,但是当一个像素受到超过四个纹素的影响时,过滤器很快就会失败并产生锯齿。
更好的解决方案是可能的。如第5.4.1节所述,可以通过采样和滤波技术解决失真问题。纹理的信号频率取决于其纹理像素在屏幕上的间隔距离。由于奈奎斯特极限,我们需要确保纹理的信号频率不大于采样频率的一半。 例如,假设图像由交替的黑线和白线组成,每条间隔一个纹素。 然后波长为两个纹素宽(从黑线到黑线),因此频率为1/2。为了在屏幕上正确显示该纹理,频率必须至少为2×1/2,即至少一个像素/纹素。因此,对于一般的纹理,每个像素最多应该只有一个纹素,以避免混叠。
为了实现这一目标,要么像素的采样频率增加,要么纹理频率降低。前一章中讨论的抗锯齿方法提供了增加像素采样率的方法。 然而,这些仅使采样频率有限地增加。 为了更全面地解决这个问题,已经开发了各种纹理缩小算法。
所有纹理抗锯齿算法背后的基本思想都是相同的:预处理纹理并创建数据结构,这将有助于快速计算一组纹素在一个像素中的近似。对于实时工作,这些算法具有使用固定数量的时间和资源来执行的特征。以这种方式,每个像素拍摄固定数量的样本并组合了(可能大量的)纹素的效果。
Mipmapping
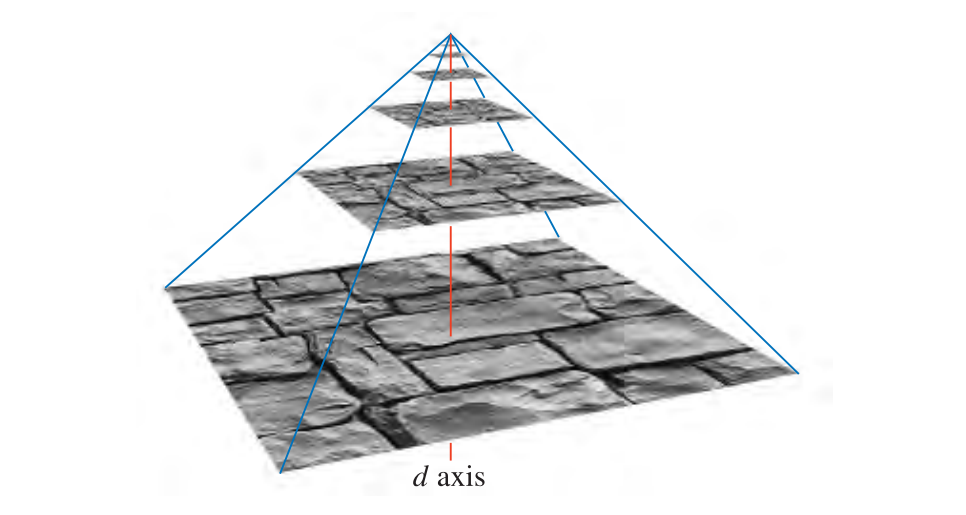
最受欢迎的纹理抗锯齿方法称为mipmapping。它以某种形式在现在生产的所有图形加速器上实现。 “Mip”代表“multum in parvo”,拉丁语,代表“很小的地方有很多东西”:对于将原始纹理重复过滤为较小图像的过程而言,这是一个不错的名字。
当使用mipmapping minimization filter时,在实际渲染发生之前,使用一组小号纹理来扩充原始纹理。纹理(原始纹理属于level zero)被下采样到原始区域的四分之一,每个新纹素值通常被计算为原始纹理中四个相邻纹素的平均值。新的,level-one纹理有时被称为原始纹理的子纹理。递归地执行缩小,直到纹理的一个或两个维度等于一个纹素。 如图,整个图像集通常称为mipmap chain:
生成高质量mipmap的两个重要因素是良好的滤波和伽马校正。生成mipmap级别的常用方法是采用每组2×2的纹素并对其进行平均以获得mip纹素值。 使用的过滤器是盒式过滤器。 这可能导致质量差,因为它具有不必要地模糊低频的效果,同时保持一些导致失真的高频。最好使用Gaussian,Lanczos,Kaiser或类似的滤波器;这些滤波器都有免费的源代码,且一些GPU支持的API可以提供更好的过滤。在纹理的边缘部分,需要注意过滤期间是重复纹理还是简单拷贝。
对于在非线性空间中编码的纹理(例如大多数颜色纹理),在过滤时忽略伽马校正,这将影响纹理的感知亮度。 当您离物体越来越远并且使用未经校正的mipmaps时,物体整体看起来会更暗,对比度和细节也会受到影响。因此,将这些纹理从sRGB转换为线性空间是非常重要的,在该空间中执行所有mipmap过滤,并将最终结果转换回sRGB颜色空间进行存储。大多数API都支持sRGB纹理,因此将在线性空间中正确生成mipmap并将结果存储在sRGB中。 访问sRGB纹理时,首先将它们的值转换为线性空间,以便正确执行放大和缩小。
如前所述,一些纹理与最终的着色颜色有着根本的非线性关系。这通常会导致过滤问题,由于过滤了数百或数千个像素,因此mipmap生成对此问题特别敏感。通常需要专门的mipmap生成方法以获得最佳结果。这些方法详见9.13节。
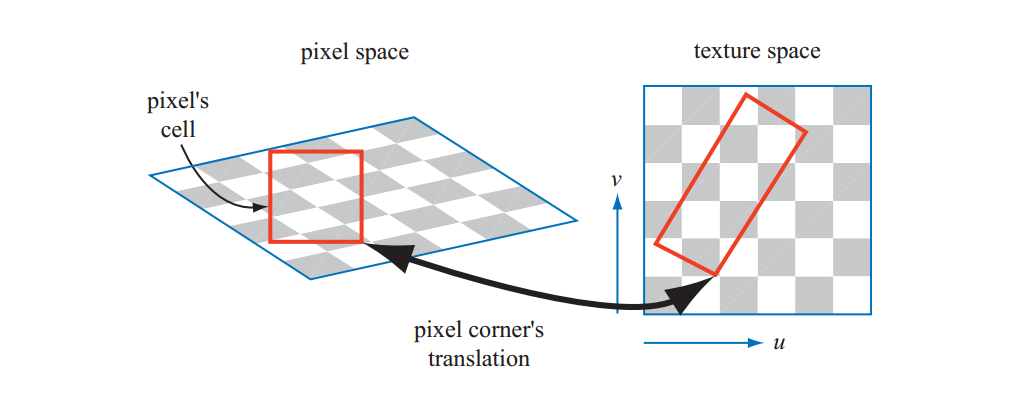
纹理化时访问此结构的过程很简单。屏幕像素包围纹理本身的一块区域。当像素的区域投影到纹理上时,它包含一个或多个纹素。使用像素的单元格边界来演示并不严格正确,但这里使用它来简化演示过程。单元格外的纹理可以影响像素的颜色。目标是大致确定纹理对像素的影响程度。有两种常用的计算方法用于计算$d$(OpenGL称为$\lambda$,也称为细节的纹理级别,texture level of detail)。一种是使用由像素单元形成的四边形的较长边缘来近似像素的覆盖范围;另一种方法是用四个微分的最大绝对值$\partial{u}/\partial{x}$,$\partial{v}/\partial{x}$,$\partial{u}/\partial{y}$和$\partial{v}/\partial{y}$。每个微分表示纹理坐标相对于屏幕轴的变化量。例如,$\partial{u}/\partial{x}$是一个像素沿x屏幕轴的u纹理值的变化量。有关这些方程的更多信息,请参阅Williams的原始文章或Flavell或Pharr的文章。麦考马克等人讨论通过最大绝对值方法引入混叠,并且提出了一个替代公式。Ewins等人,分析了几种质量相当的算法的硬件成本。
使用Shader Model 3.0或更高版本的像素着色器程序可以使用这些渐变值。由于它们基于相邻像素中的值之间的差异,因此在受动态流控制影响的像素着色器中无法访问它们。对于要在这样的部分中执行的纹理读取(例如,在循环内部),必须更早地计算导数。请注意,由于顶点着色器无法访问渐变信息,因此需要在顶点着色器本身中计算渐变或细节级别,并在使用顶点纹理时将其提供给GPU。
计算坐标$d$的目的是确定沿着mipmap的金字塔轴采样的位置。目标是像素到纹素比率至少为$1:1$以实现奈奎斯特率。这里的重要原则是当像素单元包括更多纹素和$d$增加时,访问纹理的较小的模糊版本。$(u,v,d)$三元组用于访问mipmap。值$d$类似于纹理级别,但是$d$不是整数值,而是具有级别之间距离的小数值。上面的纹理级别和d位置下面的级别被采样。$(u,v)$位置用于从这两个纹理级别中的每一个中检索双线性插值样本。 然后,根据从每个纹理级别到$d$的距离,对得到的样本进行线性插值。整个过程称为三线性插值(trilinear interpolation),并按像素执行。
用户控制可以通过细节偏差水平(level of detail bias,LOD偏差)控制d坐标。这是一个要添加到d的值,因此它会影响纹理的清晰度。如果我们进一步向上移动金字塔(增加d),纹理将看起来更模糊。 任何给定纹理的良好LOD偏差将随图像类型和使用方式而变化。例如,开始时有些模糊的图像可能使用负偏差,而用于纹理化的不良过滤(混叠)合成图像可能使用正偏差。可以为整个纹理或像素着色器中的每个像素指定偏差。为了更精细的控制,用户可以提供用于计算它的d坐标或导数。

mipmapping的好处在于,不是试图对影响单个像素的所有纹素进行求和,而是访问和插入预组合的纹素集。无论缩小量多少,此过程都需要一定的时间。然而,mipmapping有几个缺陷。一个主要的是过度模糊(overblurring )。想象一下像素单元在u方向上覆盖大量纹素,在v方向上只有少数纹素。这种情况通常发生在观察者沿着几乎边缘的纹理表面看时。事实上,可能需要沿纹理的一个轴和另一个轴放大缩小。访问mipmap的效果是检索纹理上的方形区域;检索矩形区域是不可能的。为了避免失真,我们选择纹理上像素单元的近似覆盖范围的最大度量。这导致检索的样本通常相对模糊。这种效果可以上图中看到。向右延展的线显示过度模糊。
Summed-Area Table
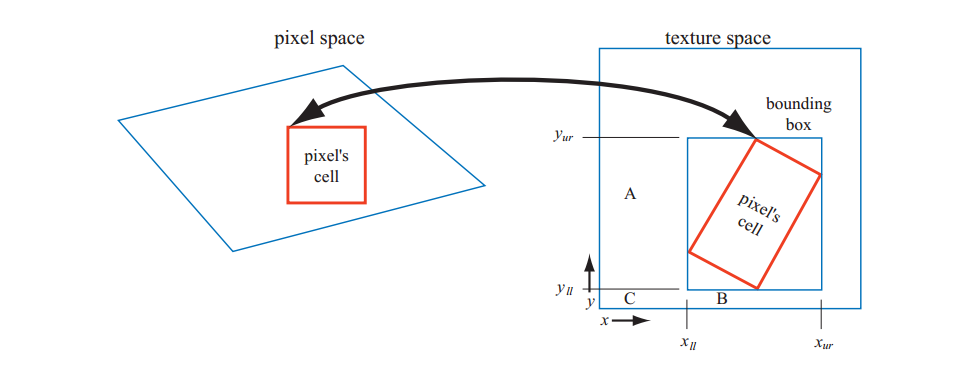
避免过度模糊的另一种方法是求和区域表(SAT)。要使用此方法,首先要创建一个数组,该数组的大小与纹理的大小相同,但包含更多的存储颜色精度位(如,对RGB中的每个16位或更多位)。在该数组中的每个位置,必须计算并存储由该位置和纹理元素$(0,0)$(原点)形成的矩形中所有相应纹理的纹素的总和。在贴图期间,像素单元在纹理上的投影由矩形约束。然后访问SAT以确定该矩形的平均颜色,该矩形作为像素的纹理颜色传回。 使用图6.17中所示矩形的纹理坐标计算平均值。这是使用下述公式完成的:
$$
\boldsymbol{c}=\frac{\boldsymbol{s}[x_{ur},y_{ur}]-\boldsymbol{s}[x_{ur},y_{ll}]-\boldsymbol{s}[x_{ll},y_{ur}]+\boldsymbol{s}[x_{ll},y_{ll}]}{(x_{ur}-x_{ll})(y_{ur}-y_{ll})}\tag{6.3}
$$
这里,x和y是矩形的纹素坐标,$\boldsymbol{s}[x, y]$是该纹素的总面积值。该等式通过获取从右上角到原点的整个区域的总和,然后通过减去相邻角落的贡献来减去区域A和B。区域C已被减去两次,因此它被添加回左下角。 注意,$(x_{ll},y_{ll})$是区域C的右上角,$(x_{ll}+1,y_{ll}+1)$是边界框的左下角。

使用求和区域表的结果如上图。 到达地平线的线条在右边缘附近更锐利,但中间的对角线交叉线仍然过于模糊。 问题在于,当沿着其对角线观察纹理时,生成大矩形,其中许多纹素位于计算的像素附近。例如,想象一个长而细的矩形,表示像素单元的背投影(back-projection)整个纹理的对角线上。 将返回整个纹理矩形的平均值,而不仅仅是像素单元格内的平均值。
求和面积表是所谓的各向异性过滤(anisotropic filtering)算法的一个例子。 此类算法在非正方形区域上检索纹素值。但是,SAT能够在主要水平和垂直方向上最有效地完成此任务。另请注意,对于大小为16×16或更小的纹理,求和区域表至少需要两倍的内存,更大的纹理需要更高的精度。
可以在现代GPU上实现总和区域表,其在合理的总存储器成本下提供更高的质量。改进的过滤器对于高级渲染技术的质量至关重要。例如,Hensley等人提供了一种有效的实现方式,并显示了求和区域采样如何改善光泽反射。 其他使用区域采样的算法可以通过SAT改进,例如景深,阴影图和模糊反射。
Unconstrained Anisotropic Filtering(无约束各向异性过滤)
对于当前的图形硬件,进一步改进纹理过滤的最常用方法是重用现有的mipmap硬件。基本思想是像素单元被反投影(back-projected),然后对纹理上的这个四边形(quad)进行多次采样,然后组合样本。如上所述,每个mipmap样本都有一个位置和一个与之相关的方形区域。该算法不是使用单个mipmap样本来近似这个四边形的覆盖范围,而是使用几个方块来覆盖四边形。四边形的较短边可用于确定d(与mipmapping不同,经常使用较长边);这使得每个mipmap样本的平均面积更小(并且模糊度更低)。四边形的长边用于创建平行于长边和四边形中间的各向异性线。当各向异性的量在1:1和2:1之间时,沿着该线取两个样本。在较高的各向异性比率下,沿轴线采集更多样本。
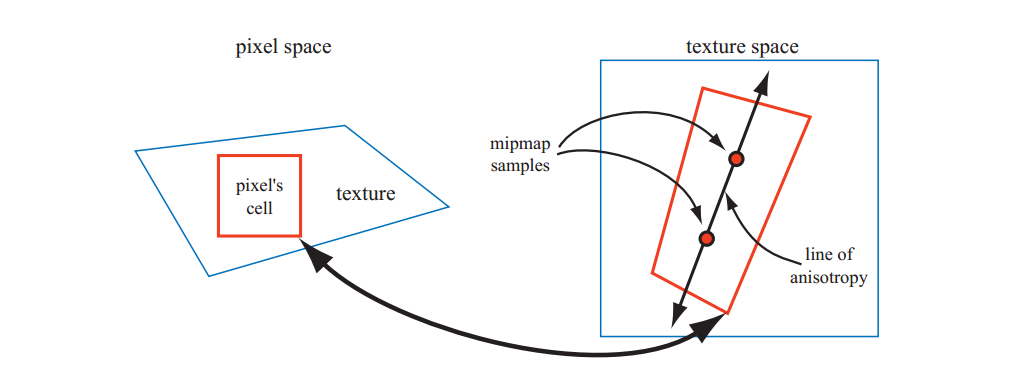
该方案允许各向异性线在任何方向上运行,因此不具有SAT的限制。它也不需要比mipmap更多的内存来存储纹理,因为它使用mipmap算法进行采样。各向异性过滤的一个例子如图:

(后面介绍了一些拓展方法,略)
6.2.3 Volume Textures(体积纹理)
图像纹理的直接扩展是通过$(u,v,w)$(或$(s,t,r)$)访问的三维图像数据。 例如,医学成像数据可以生成为三维网格;通过移动多边形通过该网格,可以查看这些数据的二维切片。一个相关的想法是以这种形式表示体积光。通过找到其在该体积内的位置的值以及光的方向来找到表面上的点上的照明。
大多数GPU支持体积纹理的mipmapping。 由于在单个体积纹理的mipmap level内进行滤波涉及三线性插值,因此在mipmap level之间进行滤波需要四线性插值(quadrilinear interpolation)。由于这涉及对来自16个纹素的结果进行平均,因此可能导致精度问题,这可以通过使用更高精度的体积纹理来解决。 Sigg和Hadwiger讨论了这个问题和与体积纹理相关的其他问题,并提供了执行过滤和其他操作的有效方法。
尽管体积纹理具有明显更高的存储要求并且过滤成本更高,但它们确实具有一些独特的优势。可以跳过为三维网格找到二维参数的复杂过程,因为三维位置可以直接用作纹理坐标。这避免了二维参数化通常发生的变形和接缝问题。体积纹理也可用于表示诸如木材或大理石的材质的体积结构。用这种材质纹理化的模型就像是用这种材质雕刻的。
使用体积纹理进行表面纹理处理是非常低效的,因为绝大多数样本都不使用。 Benson和Davis和DeBry等人讨论将纹理数据存储在稀疏八叉树结构中。该方案非常适合交互式三维绘画系统,因为表面在创建时不需要为其分配明确的纹理坐标,并且八叉树可以将纹理细节保持在任何所需的水平。Lefebvre等讨论在现代GPU上实现八叉树纹理的细节。Lefebvre和Hoppe讨论了将稀疏体积数据打包成明显更小的纹理的方法。
6.2.4 Cube Maps(立方纹理)
另一种类型的纹理是立方体纹理(cube texture、cube map),其具有六个正方形纹理,每个纹理与立方体的一个面相关联。使用三分量纹理坐标向量访问立方体贴图,该向量指定从多维数据集中心向外指向的光线的方向。光线与立方体相交的点如下所述。纹理坐标中最大的分量选择相应的面(例如,矢量$(-3.2,5.1,-8.4)$选择-z面)。剩余的两个坐标除以最大坐标的绝对值,即8.4。它们现在的范围从-1到1,然后重新映射到[0,1]以便计算纹理坐标。例如,坐标$(-3.2,5.1)$被映射到$((-3.2/8.4+1)/2,(5.1/8.4+1)/2)\approx(0.31,0.80)$。立方体贴图可用于表示作为方向函数的值,最常用于环境映射。
6.2.5 Texture Representation(纹理表示)
在应用程序中处理许多纹理时,有几种方法可以提高性能。纹理压缩在6.2.6节中描述,而本节的重点是纹理图集(texture atlas),纹理数组(texture arrays)和无绑定纹理(bindless textures),所有这些都旨在减少在渲染时更改纹理的成本。在第19.10.1节和第19.10.2节中,描述了纹理流(texture streaming)和转码(transcoding)。
为了能够让GPU批处理尽可能多的工作,最好尽可能少地改变状态。为此,可以将几个图像放入一个较大的纹理中,称为纹理图集。请注意,子纹理的形状可以是任意的。Nöll和Stricker描述了如何优化子纹理在图集中的放置。由于mipmap上层可能包含几个分离的,不相关的形状,因此还需要注意mipmap的生成和访问。Manson和Schaefer 提出了一种通过把表面参数加入考虑来优化mipmap创建的方法,这可以产生明显更好的结果。Burley和Lacewell 提出了一个名为Ptex的系统,其中细分曲面中的每个四边形都有自己的小纹理。优点是,这避免了在网格上分配唯一纹理坐标,并且在纹理图集的断开部分的接缝上没有伪影。为了能够跨四边形进行过滤,Ptex使用邻接数据结构(adjacency data structure)。虽然最初的目标是生产渲染(production rendering),但Hillesland提出了打包的Ptex,它将每个面的子纹理放入纹理图集中,并使用相邻面的填充以避免在过滤的时候间接处理。 Yuksel提出了网格颜色纹理,改进了Ptex。Toth实现一种方法来为Ptex类系统提供高质量的过滤。
使用图集的一个难点是wrapping/repeat和mirror模式,它们不会正确地影响子纹理而只影响整个纹理。在为图集生成mipmap时可能会出现另一个问题,其中一个子纹理可能会渗入另一个子纹理。但是,这可以避免,通过在将每个子纹理放置到大型纹理图集并对子纹理使用二次幂分辨率之前,分别为每个子纹理生成mipmap层次结构。

这些问题的一个更简单的解决方案是使用称为纹理数组的API结构,它完全避免了mipmapping和repeat modes的任何问题。如上图,左为纹理图集,右为纹理数组。纹理数组中的所有子纹理都需要具有相同的尺寸,格式,mipmap层次结构和MSAA设置。 像纹理图集一样,设置只对纹理数组执行一次,然后可以使用着色器中的索引访问任何数组元素。 这比绑定每个子纹理快5倍。
bindless texture可以帮助避免状态更改造成的消耗,由API支持。如果没有bindless texture,则使用API将纹理绑定到特定纹理单元。一个问题是纹理单元数量的上限,这使程序员的事情变得复杂。 驱动程序确保纹理驻留在GPU端。对于bindless texture,纹理数量没有上限,因为每个纹理只与其数据结构的64位指针(有时称为句柄)相关联。可以以许多不同的方式访问这些句柄,例如,通过uniform,通过变量,通过其他纹理,或来自着色器存储缓冲对象(SSBO)。应用程序需要确保纹理驻留在GPU端。无绑定纹理避免了驱动程序中的任何类型的绑定成本,这使得渲染更快。
6.2.6 Texture Compression(纹理压缩)
一种直接解决内存和带宽问题以及缓存问题的解决方案是固定速率的纹理压缩(texture compression)。 通过让GPU在运行中解码压缩纹理,纹理可以需要更少的纹理内存,因此增加了有效的高速缓存大小。至少同样重要的是,这样的纹理使用起来更有效,因为它们在访问时消耗更少的存储器带宽。相关但不同的用例是添加压缩以提供更大的纹理。例如,在$512^2$分辨率下使用每个纹素3个字节的非压缩纹理将占用768 kB。 使用纹理压缩,压缩比为6:1,$1024^2$的纹理将仅占用512 kB。
在图像文件格式中使用了各种图像压缩方法,例如JPEG和PNG,但在硬件中实现这些方法的解码成本很高。 S3开发了一种称为S3纹理压缩(S3TC)的方案,它被选为DirectX的标准称作DXTC,在DirectX 10中称为它被称为BC(Block Compression )。此外,它也是OpenGL的标准,因为几乎所有的GPU都支持它。它具有创建尺寸固定的压缩图像,具有独立编码的部分,并且解码简单(因此快速)的优点。图像的每个压缩部分可以独立于其他部分处理。没有共享查找表或其他依赖项,这简化了解码。
DXTC/BC压缩方案有七种变体,它们共享一些共同的属性。编码在4×4纹素块(texel blocks)上完成,也称为tiles。每个块都是单独编码的。编码基于插值。对于每个编码量,存储两个参考值(例如,颜色)。为块中的16个纹素中的每一个保存插值因子。它沿两个参考值之间的线选择一个值。 压缩仅需要存储两种颜色以及每个像素的短索引值。
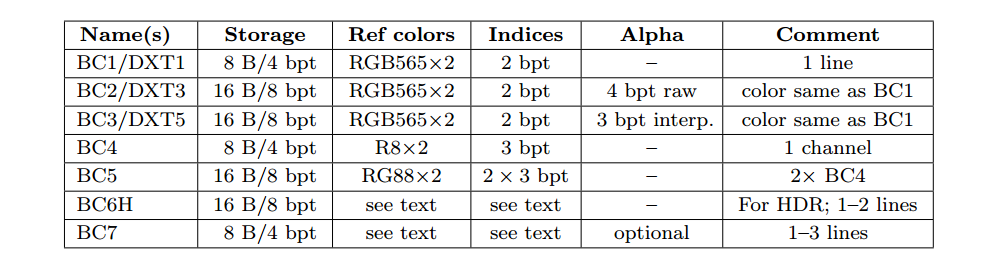
七种变体之间的确切编码有所不同,上表总结了这些变体。请注意,DXT表示DirectX 9中的名称,BC表示DirectX 10及更高版本中的名称。从表中可以看出,BC1有两个16位参考RGB值(5位红色,6位绿色,5位蓝色),每个纹素都有一个2位插值因子可选取参考值中的一个或两个中间值。与未压缩的24位RGB纹理相比,这表示纹理压缩比为6:1。BC2以与BC1相同的方式对颜色进行编码,但为了量化(原始)alpha,bits-per-texel(bpt)增加4位。对于BC3,每个块具有以与DXT1块相同的方式编码的RGB数据。此外,使用两个8位参考值和每纹素3位内插因子对alpha数据进行编码。每个纹素可以选择参考α值中的一个或六个中间值中的一个。BC4有一个通道,在BC3中编码为alpha。BC5包含两个通道,每个通道按BC3编码。
BC6H用于高动态范围(HDR)纹理,其中每个纹素最初每个R,G和B通道具有16位浮点值。 此模式使用16个字节,结果为8 bpt。 它有一种模式用于单行(类似于上面的技术),另一种模式用于两行,其中每个块可以从一小组分区中进行选择。两种参考颜色也可以进行增量编码以获得更好的精度,并且根据使用的模式也可以具有不同的精度。 在BC7中,每个块可以有一到三行,并存储8 bpt。 目标是8位RGB和RGBA纹理的高质量纹理压缩。 它与BC6H共享许多属性,但是LDR纹理的格式,而BC6H用于HDR。 注意,BC6H和BC7分别在OpenGL中称为BPTC FLOAT和BPTC。 这些压缩技术可应用于立方体或体积纹理以及二维纹理。
这些压缩方案的主要缺点是它们是有损的(lossy)。 也就是说,通常无法从压缩版本中检索原始图像。 在BC1 -BC5的情况下,仅使用四个或八个内插值来表示16个像素。 如果图块中包含大量不同的值,则会有一些损失。实际上,如果正确使用,这些压缩方案通常可提供可接受的图像保真度。
BC1 - BC5的一个问题是用于块的所有颜色都位于RGB空间的直线上。例如,红色,绿色和蓝色不能在单个块中表示。BC6H和BC7支持更多线,因此可以提供更高的质量。
对于OpenGL ES,选择另一种称为爱立信纹理压缩(Ericsson texture compression,ETC)的压缩算法包含在API中。 该方案具有与S3TC相同的特性,即快速解码,随机接入,无间接查找和固定速率。它将4×4纹素的块编码成64位,即每个纹素使用4位。基本思想如图所示。 每个2×4块(或4×2,取决于哪个给出最佳质量)存储基色。 每个块还从一个小的静态查找表中选择一组四个常量,并且块中的每个纹素都可以选择添加该表中的一个值。 这会修改每个像素的亮度。 图像质量与DXTC相当:

在包含在OpenGL ES 3.0中的ETC2中,未使用的位组合用于向原始ETC算法添加更多模式。未使用的比特组合是压缩表示(例如,64 bits),其解压缩到与另一压缩表示相同的图像。例如,在BC1中,将两个参考颜色设置为相同是没有用的,因为这将指示恒定颜色块,只要一个参考颜色包含该恒定颜色,就可以获得该颜色块。在ETC中,一种颜色也可以从具有带符号数的第一种颜色进行增量编码,因此该计算可以上溢或下溢。这种情况用于发信号通知其他压缩模式。 ETC2添加了两种新模式,四种颜色,每个块以不同的方式导出,最终模式是RGB空间中用于处理平滑过渡的平面。爱立信alpha压缩(EAC)[1868]用一个分量(例如,alpha)压缩图像。此压缩类似于基本的ETC压缩,但仅适用于一个分量,并且生成的图像每个纹素存储4位。它可以选择与ETC2结合使用,此外,还可以使用两个EAC通道来压缩法线(下面将详细介绍此主题)。所有ETC1,ETC2和EAC都是OpenGL 4.0核心配置文件,OpenGL ES 3.0,Vulkan和Metal的一部分。
法线贴图的压缩(在第6.7.2节中讨论)需要一些注意。为RGB颜色设计的压缩格式通常不适用于法线的xyz数据。 大多数方法利用已知法线为单位长度的事实,并进一步假设其z分量为正(对于切线空间法线的合理假设)。 这允许仅存储法线的x分量和y分量。 z分量是动态导出的:
$$
n_z=\sqrt{1-n_x^2-n_y^2}\tag{6.4}
$$
这本身导致适度的压缩量,因为只存储了两个分量,而不是三个。由于大多数GPU本身不支持三分量纹理,因此这也避免了浪费一个分量的可能性。 通常通过将x和y分量存储在BC5/3Dc格式纹理中来实现进一步压缩。 见下图。 由于每个块的参考值划分了最小和最大x和y分量值,因此可以将它们视为在xy平面上定义边界框。 三位插值因子允许在每个轴上选择八个值,因此bounding box被划分为可能法线的8×8网格。 或者,可以使用两个EAC通道(对于x和y),然后如上所述计算z。
在不支持BC5 / 3Dc或EAC格式的硬件上,常见的后备是使用DXT5格式纹理并将这两个分量存储在绿色和alpha分量中(因为它们以最高精度存储)。 其他两个分量未使用。
PVRTC是Imagination Technologies的硬件名为PowerVR的纹理压缩格式,其最广泛的用途是用于iPhone和iPad。 它为每个纹理元素提供2位和4位的方案,并压缩4×4纹素的块。 关键思想是提供图像的两个低频(平滑)信号,这些信号是使用相邻的纹素数据块和插值获得的。 然后,每个纹素1或2比特用于在图像上的两个信号之间进行插值。
自适应可缩放纹理压缩(Adaptive scalable texture compression ,ASTC)的不同之处在于它将n×m个纹素的块压缩成128位。 块大小范围从4×4到12×12,这导致不同的比特率,从每个纹素开始低至0.89比特,并且每个纹素高达8比特。 ASTC使用各种技巧进行紧凑索引表示,并且每个块可以选择行数和端点编码。 此外,ASTC可以处理每个纹理1-4个通道以及LDR和HDR纹理的任何内容。ASTC是OpenGL ES 3.2及更高版本的一部分。
上面提出的所有纹理压缩方案都是有损的,并且当压缩纹理时,可以在该过程上花费不同的时间量。 在压缩上花费几秒甚至几分钟,就可以获得更高的质量;因此,这通常作为离线预处理完成,并存储以供以后使用。 或者,可以花费几毫秒,结果质量较低,但纹理可以近乎实时地压缩并立即使用。 一个例子是天空盒(第13.3节),当云可能稍微移动时,它每隔一秒左右重新生成一次。由于使用固定功能硬件完成,因此解压缩速度非常快。 这种差异称为数据压缩不对称,其中压缩比解压缩花费相当长的时间。
Kaplanyan提出了几种可以改善压缩纹理质量的方法。对于包含颜色和法线贴图的纹理,建议使用每个分量16位创作贴图。对于颜色纹理,然后执行直方图重新正规化(在这16位上),然后使用着色器中的比例和偏置常量(每个纹理)反转其效果。直方图归一化是一种将图像中使用的值展开以跨越整个范围的技术,这实际上是一种对比度增强。每个组件使用16位确保在重新规范化之后直方图中没有未使用的时隙,这减少了许多纹理压缩方案可能导致的带状伪像。如下图所示。此外,如果75%的像素高于116/255,Kaplanyan建议为纹理使用线性色彩空间,否则将纹理存储在sRGB中。对于法线贴图,他还指出BC5/3Dc经常独立于y压缩x,这意味着并不总能找到最佳法线。相反,他建议对法线使用以下误差度量:
$$
e=\arccos{(\frac{\boldsymbol{n}\cdot\boldsymbol{n}_c}{\Vert\boldsymbol{n}\Vert\Vert\boldsymbol{n}_c\Vert})}\tag{6.5}
$$
其中n是原始法线,$\boldsymbol{n}_c$是相同法线的压缩后解压缩的结果。

(从左到右依次为原始贴图,每个分量8bits的DXT1,每分量16bits且在着色器中renormalization的DXT1)
应当注意,还可以在不同的颜色空间中压缩纹理,这可以用于加速纹理压缩。 常用的变换是RGB -> YCoCg:
$$
\begin{pmatrix}Y\\C_o\\C_g\end{pmatrix}=\begin{pmatrix}1/4&1/2&1/4\\1/2&0&-1/2\\-1/4&1/2&-1/4\end{pmatrix}\begin{pmatrix}R\\G\\B\end{pmatrix}\tag{6.6}
$$
其中Y是亮度,Co和Cg是色度。 逆变换也很便宜:
$$
G=(Y+C_g),t=(Y-C_g),R=t+C_o,B=t-C_o\tag{6.7}
$$
相当于一些补充。 这两个变换是线性的,可以看出,公式6.6是矩阵向量乘法,它本身是线性的(见方程4.1和4.2)。 这很重要,因为不是将RGB存储在纹理中,而是可以存储YCoCg;纹理硬件仍然可以在YCoCg空间中执行滤波,然后像素着色器可以根据需要转换回RGB。 应该注意的是,这种变换本身是有损的。
还有另一种可逆的RGB->YCoCg变换:
$$
\begin{cases}C_o=R-b\\t=B+(C_o\gg1)\\C_g=G-t\\Y=t+(C_g\gg1)\end{cases}\Longleftrightarrow\begin{cases}t=Y-(C_g\gg1)\\G=C_g+t\\B=t-(C_o\gg1)\\R=B+C_o\end{cases}\tag{6.8}
$$
其中$\gg$表示向右位移。这意味着可以在24位RGB颜色和相应的YCoCg表示之间来回转换而没有任何损失。应当注意,如果RGB中的每个分量具有n位,则Co和Cg各自具有n + 1位以保证可逆变换;Y只需要n位。 Van Waveren和Casta~no使用有损YCoCg变换在CPU或GPU上实现对DXT5/BC3的快速压缩。它们将Y存储在alpha通道中(因为它具有最高的精度),而Co和Cg存储在RGB的前两个组件中。由于Y分别存储和压缩,压缩变得很快。对于Co和Cg组件,他们找到一个二维边界框并选择产生最佳结果的方框对角线。请注意,对于在CPU上动态创建的纹理,也可以更好地压缩CPU上的纹理。当通过GPU上的渲染创建纹理时,通常最好也压缩GPU上的纹理。 YCoCg变换和其他亮度 - 色度变换通常用于图像压缩,其中色度分量在2×2像素上取平均值。这使存储减少了50%,并且通常工作正常,因为色度趋于缓慢变化。 Lee-Steere和Harmon通过转换为色调饱和度值(HSV),在x和y中将色调和饱和度下采样4倍,并将值存储为单通道DXT1纹理,更进一步。 Van Waveren和Castaño也描述了压缩法线贴图的快速方法。
Griffin和Olano的一项研究表明,当几个纹理应用于具有复杂着色模型的几何模型时,纹理的质量通常可以很低,不会有任何可察觉的差异。 因此,根据使用情况,可以接受质量下降。 Fauconneau提供了DirectX 11纹理压缩格式的SIMD实现。
6.3 Procedural Texturing(程序贴图)
给定纹理空间位置,执行图像查找是生成纹理值的一种方式。 另一种是执行函数,从而定义程序纹理。
虽然程序纹理通常用于离线渲染应用程序,但图像纹理在实时渲染中更为常见。 这是由于现代GPU中图像纹理硬件的极高效率,它可以在一秒钟内执行数十亿次纹理访问。 然而,GPU架构正朝着更便宜的计算和(相对)更昂贵的存储器访问发展。这些趋势使得程序纹理在实时应用中得到了更多的应用。
考虑到体积图像纹理的高存储成本,体积纹理是程序纹理化的一种特别有吸引力的应用。 这种纹理可以通过各种技术合成。最常见的一种是使用一个或多个噪声函数来生成值。 见下图。噪声函数通常以二次幂的频率进行采样,称为octaves。每个octave都有一个权重,通常随着频率的增加而下降,这些加权样本的总和称为湍流扰动(turbulence)函数。

由于评估噪声函数的成本,三维阵列中的格点通常被预先计算并用于内插纹理值。有各种方法使用颜色缓冲区混合来快速生成这些数组。 Perlin提供了一种快速,实用的方法来对噪声函数进行采样,并展示了一些用途。 Olano提供噪声生成算法,允许在存储纹理和执行计算之间进行权衡。麦克尤恩等人。开发用于计算着色器中的经典噪声和单纯噪声的方法,无需任何查找,并且可以使用源代码。 Parberry使用动态编程来分摊几个像素的计算,以加速噪声计算。 Green提供了一种更高质量的方法,但是对于近交互式应用程序来说更是如此,因为它使用50个像素着色器指令进行单个查找。 Perlin提出的原始噪声功能可以改进。 Cook和DeRose提供了一种称为小波噪声的替代表示,它避免了混叠问题,只是评估成本略有增加。 Liu等人使用各种噪声函数来模拟不同的木材纹理和表面处理。我们还推荐了Lagae等人在本主题中提供的最新报告。
其他程序方法也是可能的。例如,通过测量从每个位置到一组散落在空间中的“特征点”的距离来形成细胞纹理。 以各种方式映射得到的最近距离,例如,改变颜色或着色法线,产生看起来像细胞,石板,蜥蜴皮和其他自然纹理的图案。 Griffiths讨论了如何有效地找到最近邻居并在GPU上生成细胞纹理。
另一种类型的程序纹理是物理模拟的结果或一些其他交互过程的结果,例如水波纹或散布的裂缝。在这种情况下,程序纹理可以在对动态条件的反应中产生无限可变性。
当生成二维程序纹理时,参数化问题可能比创作纹理带来更多困难,因为创作纹理可以通过手动修正伪像。一种解决方案是通过将纹理直接合成到表面上来完全避免参数化。在复杂曲面上执行此操作在技术上具有挑战性,并且是一个活跃的研究领域。见Wei等人有关此领域的概述。
抗锯齿程序纹理比抗锯齿图像纹理更难,也可以说更容易。 一方面,诸如mipmapping之类的预计算方法不可用,这给程序员带来了负担。另一方面,程序纹理作者具有关于纹理内容的“内部信息”,因此可以定制它以避免混叠。 对于通过对多个噪声函数求和而创建的程序纹理尤其如此。每个噪声函数的频率是已知的,因此可以丢弃任何会导致混叠的频率,实际上使计算成本更低。有许多用于对其他类型的程序纹理抗锯齿的技术。多恩等人讨论了先前的工作并提出了一些重构纹理函数的过程,以避免高频,即带限。
6.4 Texture Animation(贴图动画)
应用于表面的图像不必是静态的。 例如,视频源可以用作逐帧变化的纹理。
纹理坐标也不必是静态的。 应用程序设计人员可以在网格数据本身或通过顶点或像素着色器中应用的函数明确地逐帧更改纹理坐标。想象一下,瀑布已被建模,并且已经使用看起来像落水的图像进行纹理化。假设v坐标是流动的方向。为了使水移动,必须从每个连续帧上的v坐标中减去一定量。此操作使纹理本身看起来向前移动的效果。
通过将矩阵应用于纹理坐标可以创建更精细的效果。除了平移之外,还允许使用线性变换,例如缩放,旋转和剪切,图像变形和变形变换以及投影。通过在CPU或着色器中应用函数,可以创建更多精细的效果。
通过使用纹理混合技术,可以实现其他动画效果。例如,从大理石纹理开始,淡入进肉体纹理,就可以让雕像活过来。
6.5 Material Mapping(材质映射)
纹理的常见用途是修改影响着色方程的材质属性。真实世界的物体通常具有在其表面上变化的材质特性。要模拟此类对象,像素着色器可以从纹理中读取值,并在计算着色方程之前使用它们来修改材质参数。最常由纹理修改的参数是表面颜色。此纹理称为albedo color map或diffuse color map。但是,任何参数都可以通过纹理进行修改:替换它,将其相乘或以其他方式更改它。例如,在下图中,三个不同的纹理应用于曲面,替换常量值。

可以使用纹理来控制像素着色器本身的流程和功能,而不是修改等式中的参数。通过使一个纹理指定表面的哪个区域具有哪种材质,可以将具有不同着色方程和参数的两种或更多种材料应用于表面,从而让每种材料执行不同的代码。 例如,具有一些生锈区域的金属表面可以使用纹理来指示生锈所在的位置,以区分光亮部分。
如表面颜色的着色模型输入与着色器的最终颜色输出呈线性关系。因此,可以使用标准技术对包含这些输入的纹理进行滤波,并避免混叠。包含非线性着色输入的纹理(如粗糙度或凹凸贴图(第6.7节))需要更加小心以避免混叠。着色方程的滤波技术可以改善这种纹理的结果。第9.13节讨论了这些技术。
6.6 Alpha Mapping(透明度映射)
使用alpha混合或alpha测试可以将alpha值用于许多效果,例如有效渲染树叶,爆炸和远处物体等等。本节讨论纹理与alphas的使用,各种限制和解决方案。
一种与纹理相关的效果贴花(decaling)。举个例子,假设您想在茶壶上放一朵花的照片。你不想要整个画面,而只想要花朵所在的部分。通过为纹素分配一个值为0的alpha,你可以使它透明,这样它就没有效果了。因此,通过正确设置贴花纹理的alpha,可以用贴花replace或blend底层表面。通常,夹具对应器功能与透明边框一起使用以将贴花的单个副本(相对于重复纹理)应用于表面。下图显示了如何实现decaling的示例。有关贴花的更多信息,请参见第20.2节。
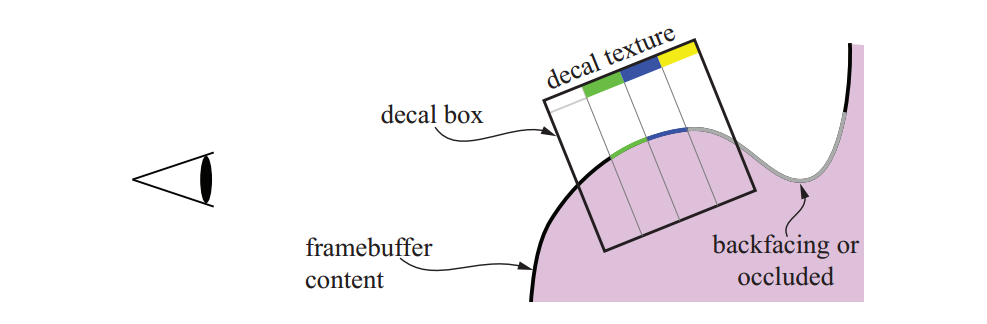
(实现贴花的一种方法。 首先使用场景渲染帧缓冲区,然后渲染一个box,对于box内的所有点,将贴花纹理投影到帧缓冲区内容。 最左边的纹素是完全透明的,因此它不会影响帧缓冲。 黄色纹理像素不可见,因为它会被投射到表面的隐藏部分。)
alpha的一个类似应用是制作cutouts。 假设您制作灌木的贴花图像并将其应用于场景中的矩形。 原理与贴花相同,除了不是与下面的表面齐平,灌木将被绘制在其后面的任何几何形状的顶部。通过这种方式,您可以使用单个矩形渲染具有复杂轮廓的对象。
在灌木的情况下,如果您围绕它旋转着观察,则导致问题,因为衬套没有厚度。一个方法是复制这个灌木矩形并沿着树干旋转90度。这两个矩形形成了一个廉价的三维灌木丛,有时被称为“十字树”(cross tree),从地面看,效果不错。见下图。

Pelzer讨论了一个类似的配置,使用三个cutout(第13.6节),我们讨论了一种叫做广告牌(billboarding)的方法,它用于将这种渲染减少到一个矩形。如果观察者移动到地面以上,则从上方看到灌木是两个cutout时,错觉就会破裂。请参见下图。为了解决这个问题,可以以不同的方式添加更多cutout,如切片,分支,层以提供更有说服力的模型。

结合alpha贴图和纹理动画可以产生令人信服的特殊效果,例如闪烁的火把,植物生长,爆炸和大气效果。
使用alpha贴图渲染对象有多种方式。Alpha blending(第5.5节)允许使用带小数的透明度值,这样可以对对象边缘以及部分透明对象进行抗锯齿处理。但是,alpha混合需要在不透明的三角形渲染之后再渲染需要混合的三角形,并且按照从前到后的顺序渲染。简单的交叉树是两个剪切纹理的示例,不使用渲染顺序是正确的,因为每个四边形位于另一个的一部分的前面。即使理论上可以排序并获得正确的顺序,这样做通常也是低效的。 例如,田地可能有成千上万的草叶片,由切口代表。 每个网格对象可以由许多单独的叶片制成。对每个叶片进行排序是非常不切实际的。
在渲染时,可以通过几种不同的方式改善此问题。一种是使用alpha测试,这是在像素着色器中有条件地丢弃具有低于给定阈值的α值的片段的过程:
if (texture.a < alphaThreshold) discard; \\ (6.9)
其中texture.a是纹理查找的alpha值,参数alphaThreshold是用户提供的阈值,用于确定将丢弃哪些片段。这种二元可见性测试使三角形能够以任何顺序呈现,因为透明片段被丢弃。我们通常希望对alpha为0.0的任何片段执行此操作。丢弃完全透明的片段还有一个额外的好处,即可以节省更多的着色器处理和合并成本,同时避免错误地将z缓冲区中的像素标记为可见。对于cutout,我们经常将阈值设置为高于0.0,比如0.5或更高,然后采取进一步的步骤,然后完全忽略alpha值,而不是使用它进行混合。这样做可以避免乱序伪像(out-of-order artifacts)。但是,质量很低,因为只有两级透明度(完全不透明和完全透明)可用。另一个解决方案是为每个模型执行两次pass:一次用于solid cutouts,写入z-buffer,另一次用于半透明样本,而不写入z-buffer。
alpha测试还有另外两个问题,即放大倍数太大和缩小太多。当alpha测试与mipmapping一起使用时,如果处理方式不同,效果可能会令人难以置信。下图顶部显示了一个示例,其中树的叶子变得比预期更透明。

这可以用一个例子来解释。假设我们有一个具有四个alpha值的一维纹理,即(0.0,1.0,1.0,0.0)。通过平均,下一个mipmap级别变为(0.5,0.5),然后最高级别为(0.5)。 现在,假设我们使用$\alpha_t=0.75$。 当访问mipmap级别0时,可以显示4个中的1.5纹素将在discard测试中留存。但是,当访问接下来的两个级别时,从0.5 < 0.75开始,所有内容都将被丢弃。有关另一个示例,见下图:

(在顶部是具有混合的叶子图案的不同mipmap级别,较高级别为了可见性而缩放。 在底部显示将使用0.5为阈值的alpha测试进行处理的mipmap,显示对象在后退时如何具有更少的像素。)
Castaño提供了一个在mipmap创建过程中完成的简单解决方案。 对于mipmap级别k,覆盖范围$c_k$定义为:
$$
c_k=\frac1{n_k}\sum\limits_i(\alpha(k,i)\gt\alpha_t)\tag{6.10}
$$
其中$n_k$是mipmap级别k中的纹素的数量,$\alpha(k,i)$是来自像素i处的mipmap级别k的alpha值,并且$\alpha_t$是等式6.9中的用户提供的α阈值。这里,我们假设$\alpha(k,i)\gt\alpha_t$的结果如果为真则为1,否则为0。 注意,k = 0表示最低的mipmap级别,即原始图像。 对于每个mipmap级别,我们然后找到新的mipmap阈值$\alpha_k$,而不是使用$α_t$,使得$c_k$等于$c_0$(或尽可能接近)。这可以使用二进制搜索来完成。 最后,mipmap级别k中所有纹素的alpha值按$α_t=α_k$缩放。此方法用于上上图底部,并且在NVIDIA的纹理工具中支持此方法。Golus提供了一个不修改mipmap的变体,但是随着mipmap级别的增加,alpha会在着色器中放大。
Wyman和McGuire提出了一个不同的解决方案,其中公式6.9中的代码行在理论上被替换为:
if (texture.a < random()) discard; \\ (6.11)
随机函数在[0,1]中返回一个统一值,这意味着平均来说这将得到正确的结果。 例如,如果纹理查找的alpha值为0.3,则将以30%的几率丢弃该片段。这是一种随机透明的形式,每个像素有一个样本。在实践中,随机函数被替换为hash函数以避免时间和空间高频噪声:
float hash2D(x,y) {return fract(1.0e4*sin(17.0*x+0.1*y)*(0.1+abs(sin(13.0*y+x))));} \\ 6.12
通过对上述函数的嵌套调用形成三维hash,即,float hash3D(x,y,z) {return hash2D(hash2D(x,y),z); },返回[0,1)。hash的输入是object-space坐标除以object-space坐标的x和y中屏幕空间导数最大的那一个,然后clamping。需要进一步注意以获得z方向上的运动的稳定性,并且该方法最好与temporal抗锯齿技术相结合。这种技术随着距离逐渐消失,因此近距离我们根本没有任何随机效应。这种方法的优点是每个片段平均是正确的,而Castaño的方法为每个mipmap级别创建一个单独的$α_k$。 但是,此值可能会因每个mipmap级别而异,这可能会降低质量并需要艺术家干预。
Alpha测试显示放大倍数下的纹波伪影,可以通过将alpha贴图预先计算为距离场来避免。
Alpha to coverage,以及类似的特征透明度自适应抗锯齿,获取片段的透明度值并将其转换为覆盖像素内的样本个数。这个想法就像screen-door透明度(5.5节),但是是在子像素级别。想象一下,每个像素有四个样本位置,一个片段覆盖一个像素,但是25%透明(75%不透明)。alpha to coverage模式使片段变得完全不透明,但它只覆盖四个样本中的三个。此模式对于重叠草叶的切割纹理非常有用。由于绘制的每个样本都是完全不透明的,因此最接近的样本将沿着其边缘以一致的方式隐藏其后面的对象。 由于α混合已关闭,因此对正确混合半透明边缘像素不需要进行排序。
Alpha到覆盖范围有利于抗锯齿alpha测试,但在alpha混合时会失真。例如,具有相同alpha覆盖百分比的两个alpha混合片段将使用相同的子像素模式,这意味着一个片段将完全覆盖另一个片段而不是与其混合。Golus讨论了使用fwidth()着色器指令为内容提供更清晰的边缘。 见下图。

(-> alpha test, alpha blend, alpha to coverage, and alpha to coverage with sharpened edges)
对于alpha映射的任何使用,了解双线性插值如何影响颜色值非常重要。想象一下彼此相邻的两个纹素:rgbα=(255,0,0,255)是纯红色,其邻居rgbα=(0,0,0,2)是黑色且几乎完全透明。正好在两个纹素之间的位置的rgbα是什么?简单的插值给出(127,0,0,128),结果rgb值是一个"暗淡的"红色。但是,这个结果实际上并不是暗淡的,它是一个完整的红色,被它的alpha预乘。对于正确的插值,你需要确保被插值的颜色在插值之前已经被alpha预乘。例如,假设几乎透明的邻居设置为rgbα=(0,255,0,2),一个稍稍显绿的色调。这种颜色不预乘时,将给出结果(127,127,0,128),插入微小的绿色调突然将变为一个黄色样本。预乘后的这个相邻纹素是(0,2,0,2),再进行插值时,它给出了正确的预乘结果(127,1,0,128)。这个结果更有意义,产生的预乘颜色大部分是红色的,带有难以察觉的绿色色调。
忽略双线性插值的结果给出预乘结果可能导致贴花和cutout对象周围的黑边。"暗淡的"红色结果被管线的其余部分视为未经预乘的颜色,边缘变为黑色。即使使用alpha测试,这种效果也可以看到。最好的策略是在双线性插值完成之前进行预乘。WebGL API支持这一点,因为合成对于网页很重要。但是,双线性插值通常由GPU执行,并且在执行此操作之前,着色器无法对纹素值进行操作。图像不会以PNG等文件格式预乘,因为这样做会失去颜色精度。这两个因素在使用alpha映射时默认会导致黑边缘。一个常见的解决方法是预处理cutout图像,绘制透明,“黑色”纹素使用来自附近不透明纹理像素的颜色。所有透明区域通常需要通过手动或自动方式重新绘制,以便mipmap级别也可以避免边缘问题。值得注意的是,在形成具有α值的mipmap时应使用预乘值。
6.7 Bump Mapping(凹凸映射)
本节描述了一大类小规模细节表示技术,我们统称为凹凸贴图。 通常通过修改每像素着色例程来实现所有这些方法。 它们比单独的纹理映射提供更多的三维外观,但不添加任何其他几何体。
对象上的细节可以分为三个尺度:覆盖许多像素的宏观特征,跨越几个像素的中观特征,以及远小于像素的微观特征。这些类别在某种程度上是流动的,因为观看者可以在动画或交互式会话期间在许多距离处观察相同的对象。
宏观几何体由顶点和三角形或其他几何图元表示。 在创建三维角色时,肢体和头部通常以宏观尺度建模。微观几何体被封装在着色模型中,该模型通常在像素着色器中实现,并使用纹理贴图作为参数。所使用的着色模型模拟表面的微观几何形状的相互作用,例如,闪亮的物体在显微镜下是光滑的,而漫射的表面在微观上是粗糙的。角色的皮肤和衣服看起来具有不同的材质,因为它们使用不同的着色器,或者在这些着色器中使用至少不同的参数。
中间尺度描述了这两个尺度之间的所有内容。它包含无法使用单个三角形进行高效渲染的复杂细节,但又足以让观察者区分表面上几个像素的曲率的个别变化。角色脸上的皱纹,肌肉细节,衣服上的褶皱和接缝都是中尺度的。一系列统称为凹凸贴图技术的方法通常用于中尺度建模。这些调整像素级别的阴影参数,使得观察者感觉到远离基本几何形状的小扰动,其实际上保持平坦。不同类型的凹凸贴图之间的主要区别在于它们如何表示细节特征。变量包括现实主义的水平和细节特征的复杂性。例如,数字艺术家通常将细节雕刻到模型中,然后使用软件将这些几何元素转换为一个或多个纹理,例如凹凸纹理和可能是crevice-darkening纹理。
Blinn在1978年提出了在纹理中编码中尺度细节的想法。 他观察到,如果在着色期间,我们用一个略微扰动的表面法线取代真实的表面,则表面似乎具有小尺度细节。 他将描述扰动的数据存储到曲面法线的数组中。
关键的想法是,我们不是使用纹理来改变照明方程中的颜色分量,而是访问纹理来修改表面法线。表面的几何法线保持不变;我们只修改照明方程中使用的法线。此操作没有物理等效物;我们对表面法线进行了更改,但表面本身在几何意义上保持平滑。正如每个顶点具有法线给出三角形之间表面平滑的错觉,修改每个像素的法线会改变三角形表面本身的感知,而不会修改其几何形状。
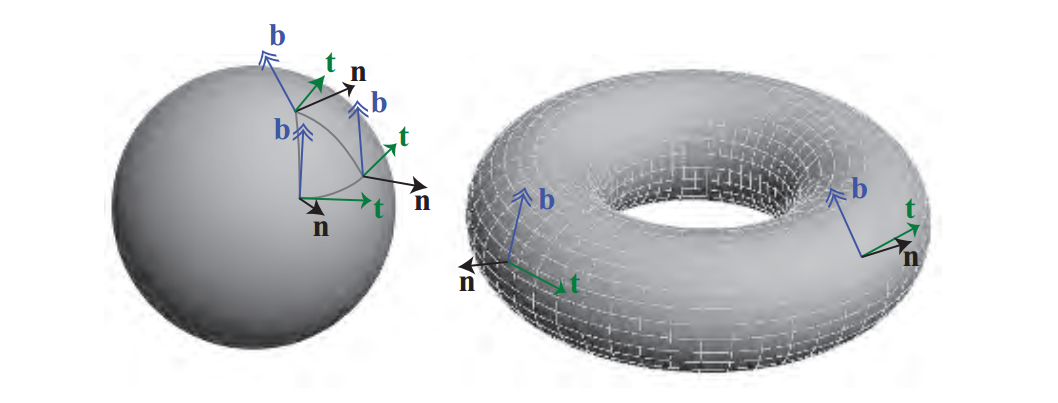
对于凹凸贴图,法线必须相对于某个参照系改变方向。为此,在每个顶点处存储tangent frame,也称为切线空间。 该参照系用于将光转换为表面位置的空间(反之亦然)以计算扰动法线的效果。对于应用了法线贴图的多边形表面,除了顶点法线之外,我们还存储了所谓的切线(tangent)和次切线(bitangent)向量。bitangent vector也被错误地称为binormal vector(次法线向量,副法线...)。
切线和切线矢量表示法线贴图本身在对象空间中的轴,因为目标是将光线转换为与贴图相关。见下图:
这三个向量,normal n,tangent t和bitangent b,形成基矩阵:
$$
\begin{pmatrix}
t_x&t_y&t_z&0\\
b_x&b_y&b_z&0\\
n_x&n_y&n_z&0\\
0&0&0&1\\
\end{pmatrix}\tag{6.13}
$$
该矩阵(有时缩写为TBN)将光的方向(对于给定的顶点)从世界空间转换为切线空间。这些矢量不必彼此真正垂直,因为法线贴图本身可能会扭曲以适合表面。然而,非正交基导致了纹理的偏斜,这可能意味着需要更多的存储并且还可能具有性能影响,因为,矩阵不能通过简单的转置反转。一种节省记忆的方法是在顶点处仅存储切线和副切线,并使用它们的叉积来计算法线。然而,这种技术只有在矩阵的左右手性始终相同时才有效。模型通常是对称的:飞机,人类,文件柜和许多其他物体。由于纹理消耗大量内存,因此它们通常镜像到对称模型上。因此,仅存储对象纹理的一侧,但纹理映射将其放置在模型的两侧。在这种情况下,切线空间的左右手性在两侧是不同的,并且不能被假设。如果在每个顶点存储额外的信息以指示左右手性,则仍然可以避免在这种情况下存储法线。如果置位,则该位用于抵消切线和bitangent的交叉积,以产生正确的法线。如果切线框架是正交的,也可以将基存储为四元数(第4.3节),这两者都更节省空间并且可以节省每个像素的一些计算。可能会有轻微的质量损失,但在实践中很少见到。
切线空间的概念对于其他算法很重要。正如下一章所讨论的,许多着色方程仅依赖于曲面的法线方向。然而,与表面相比,诸如拉丝铝或天鹅绒之类的材料也需要知道观察者和照明的相对方向。切线框架可用于定义材料在曲面上的方向。Lengyel和Mittring的文章对该领域进行了广泛的报道。 Schüler提出了一种在像素着色器中即时计算切线空间基础的方法,无需在每个顶点存储预先计算的切线框架。Mikkelsen改进了这种技术,并推导出一种不需要任何参数化的方法,而是使用表面位置的导数和高度场的导数来计算扰动法线。然而,与使用标准切线空间映射相比,这样的技术可以导致细节显着减少,并且可能产生艺术工作流问题。
6.7.1 Blinn‘s Methods
Blinn的原始凹凸贴图方法在纹理中的每个纹素处存储两个有符号值$b_u$和$b_v$。这两个值对应于沿u和v图像轴改变法线的量。 也就是说,这些通常是双线性插值的纹理值用于缩放垂直于法线的两个矢量。这两个向量被添加到法线以改变其方向。$b_u$和$b_v$描述了表面朝向该点的方向。见下图。这种类型的凹凸贴图纹理称为偏移矢量凹凸贴图(offset vector bump map)或偏移贴图(offset map)。
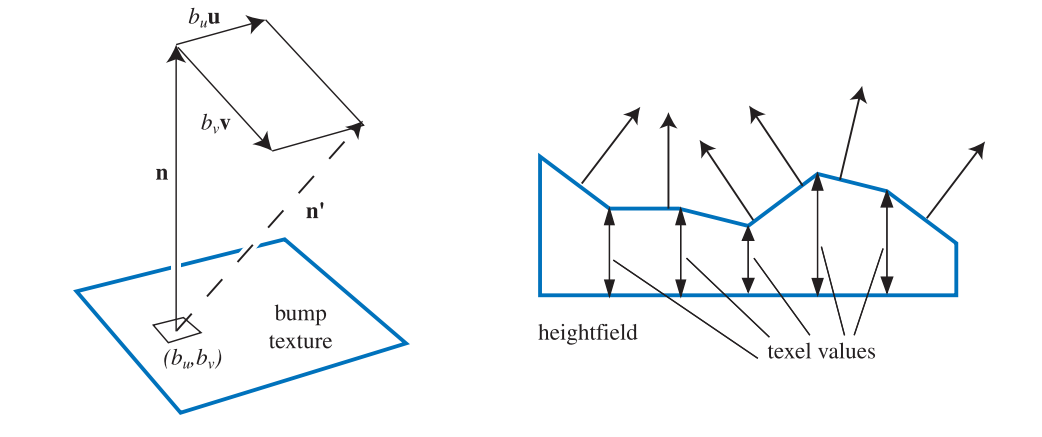
表示凸起的另一种方法是使用高度场来修改曲面法线的方向。 每个单色纹理值表示高度,因此在纹理中,白色是高区域而黑色是低区域(反之亦然)。有关示例,请参见下图。这是第一次创建或扫描凹凸贴图时使用的常见格式,它也是由Blinn于1978年引入的。高度场用于导出u和v符号值,类似于第一种方法中使用的值。通过获取相邻列之间的差异来获得u的斜率以及相邻行之间的差异获得v。一种变体是Sobel滤波器,它为直接相邻的行列提供更大的权重。

6.7.2 Normal Mapping
凹凸贴图的常用方法是直接存储法线贴图。算法和结果在数学上与Blinn的方法相同;只有存储格式和像素着色器计算会发生变化。
法线贴图编码(x,y,z)映射到[-1,1]。例如,对于8-bits纹理,x轴值0表示-1.0,并且255表示1.0。如下图所示。颜色[128,128,255],浅蓝色表示用于所示颜色映射的平坦表面,法线为[0,0,1]。
法线贴图最初是以世界空间引入的,在实践中很少使用。对于那种类型的映射,扰动是直截了当的:在每个像素处,从贴图中检索法线并直接使用它以及一个光的方向来计算表面上该位置的着色。也可以在对象空间中定义法线贴图,以便可以旋转模型,然后法线仍然有效。但是,world和object-space表示将纹理绑定到特定方向的特定几何体,这限制了纹理重用。
相反,扰动法线通常在切线空间中检索,即相对于表面本身。这允许表面变形,以及正常纹理的最大重用。切线空间法线贴图也可以很好地压缩,因为z分量的符号(与未扰动的表面法线对齐的符号)通常可以假定为正。
可以使用法线贴图来提高实际效果:

与过滤颜色纹理相比,过滤法线贴图是一个难题。通常,法线和阴影颜色之间的关系不是线性的,因此标准滤波方法可能导致混叠。想象一下,看着由闪亮的白色大理石块组成的楼梯。在某些角度,楼梯的顶部或侧面捕捉光线并反射出明亮的镜面高光。但是,楼梯的平均法线是45度角;它将捕捉与原始楼梯完全不同的方向的亮点。如果在没有正确过滤的情况下渲染具有清晰镜面反射高光的凹凸贴图,则会出现令人分心的闪光效果。
Lambertian 表面是一种特殊情况,法线贴图对着色具有几乎线性的影响。Lambertian 着色几乎完全是点积,这是线性运算。对一组法线求平均值并使用结果执行点积相当于平均各个点积与法线:
$$
\boldsymbol{l}\cdot(\frac{\sum_{j=1}^n\boldsymbol{n}_j}{n})=\frac{\sum_{j=1}^n(\boldsymbol{l}\cdot\boldsymbol{n}_j)}{n}\tag{6.14}
$$
请注意,平均向量在使用前未标准化。 公式6.14表明,标准滤波和mipmap几乎可以为Lambertian曲面生成正确的结果。但结果不太正确,因为Lambertian 着色方程不是点积;它是一个clamped点积:$max(l\cdot{n},0)$。clamp操作使其非线性。这会使表面过度变暗以掠过光线方向,但实际上这通常并不令人反感。需要注意的是,一些通常用于法线贴图的纹理压缩方法(例如从其他两个重建z-component)不支持非单位长度法线,因此使用非标准化法线贴图可能会造成压缩困难。
在非Lambertian表面的情况下,通过将输入以组的形式使用shader过滤而不是单独过滤法线贴图,可以产生更好的结果。第9.13节讨论了这样做的技巧。
最后,从高度图$h(x,y)$导出法线贴图可能很有用。首先,使用居中差异计算x和y方向上的导数的近似值:
$$
h_x(x,y)=\frac{h(x+1,y)-h(x-1,y)}{2},h_y(x,y)=\frac{h(x,y+1)-h(x,y-1)}{2}\tag{6.15}
$$
然后texel(x,y)处的非标准化法线为(必须注意纹理的边界):
$$
\boldsymbol{n}(x,y)=(-h_x(x,y),-h_x(x,y),1)\tag{6.16}
$$
通过使凹凸能够将阴影投射到它们自己的表面上,可以使用horizon mapping(水平映射)来进一步增强法线贴图。这是通过预先计算其他纹理来完成的,每个纹理与沿着表面平面的方向相关联,并为每个纹素存储该方向上的水平角度。
6.8 Parallax Mapping(视差映射)
凸点和法线贴图的问题在于凸块永远不会随着视角移动位置,也不会相互阻挡。 例如,如果你沿着一个真正的砖墙看,在某个角度,你将看不到砖之间的砂浆。墙的凹凸贴图永远不会显示这种类型的遮挡,因为它只会改变法线。最好让凸起实际上影响在每个像素上渲染表面上的位置。
视差映射的概念由Kaneko于2001年引入,并由Welsh进行了改进和推广。视差指的是当观察者移动时物体的位置相对移动的想法。 当观察者移动时,凸起应该看起来具有高度。视差映射的关键思想是通过检查发现的可见高度来对像素中应该看到的内容进行有根据的猜测。
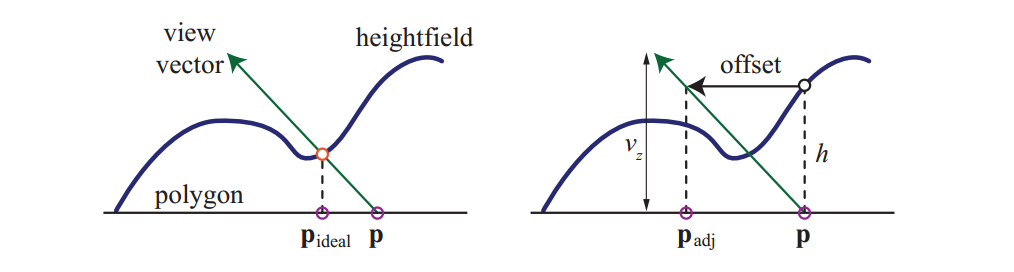
对于视差映射,bumps存储在高度场纹理中。当在给定像素处查看表面时,在该位置处检索高度场值并移动纹理坐标以检索表面的不同部分。移位量取决于检索的高度和眼睛与表面的角度。见上图。
高度值要么存储在单独的纹理中,要么打包在未使用的颜色或某些其他纹理的alpha通道中(在将不相关的纹理打包在一起时必须小心,因为这会对压缩质量产生负面影响)。在移动坐标之前,高度场值被缩放和偏斜。缩放确定高度场在表面上方或下方延伸的高度,并且偏差给出了“水平面”没有发生位移的高度。给定纹理坐标位置p,调整后的高度场高度h,以及具有高度值$v_z$和水平分量$\boldsymbol{v}_{xy}$的归一化视图向量$\boldsymbol{v}$,新的视差调整纹理坐标$p_{adj}$是
$$
\boldsymbol{p}_{adj}=\boldsymbol{p}+\frac{h\cdot\boldsymbol{v}_{xy}}{v_z}\tag{6.17}
$$
注意,与大多数着色方程不同,这里进行计算的空间与视图向量有关,需要在切线空间中。
虽然这是一个简单的近似,但如果凸起高度变化相对较慢,这种变换在实践中效果相当好。 然后,附近的相邻纹素具有相同的高度,因此使用原始位置的高度作为对新位置高度的估计的想法是合理的。然而,这种方法在浅视角下会分崩离析。当视图矢量靠近表面的地平线时,较小的高度变化会导致较大的纹理坐标偏移。近似失败,因为检索到的新位置与原始表面位置的高度相关性很小或没有。
为了改善这个问题,Welsh提出了偏移限制的想法。 这个想法是限制移动量永远不会大于检索到的高度:
$$
\boldsymbol{p}'_{adj}=\boldsymbol{p}+h\cdot\boldsymbol{v}_{xy}\tag{6.18}
$$
请注意,此等式比原始等式更快。几何学上的解释是高度定义了一个半径,超出该半径,位置不能移动:
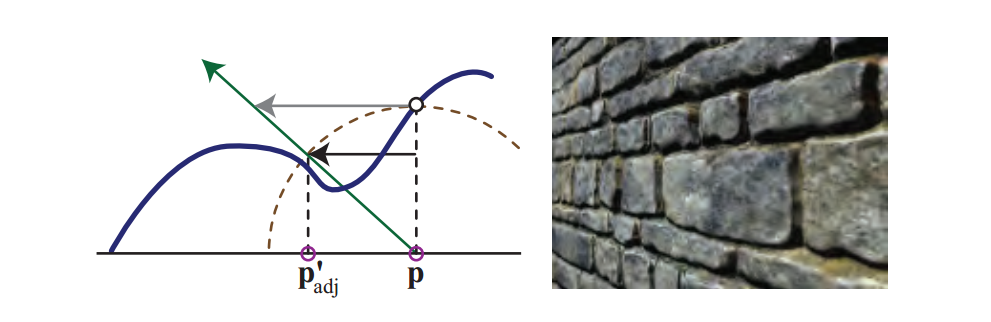
在陡峭(面朝上)的角度下,该方程几乎与原始方程相同,因为$v_z$接近1。在小角度处,偏移的效果受到限制。 在视觉上,这使得凹凸在较小角度处减小,但这比纹理的随机采样要好得多。当视图改变时,纹理游泳也存在问题,或者对于立体渲染,观察者同时感知两个必须提供一致深度提示的视点。即使存在这些缺点,具有偏移限制的视差映射仅花费一些额外的像素着色器程序指令,并且相对于基本法线贴图提供了相当大的图像质量改进。 Shishkovtsov通过在凹凸贴图法线方向上移动估计位置来改善视差遮挡的阴影。
6.8.1 Parallax Occlusion Mapping(视差遮蔽映射)
凹凸贴图不会根据高度场修改纹理坐标;它只改变某个位置的着色法线。视差映射提供了高度场效果的简单近似,假设像素处的高度与其邻居的高度大致相同。这个假设很快就会崩溃。起伏也可以永远不会相互遮挡,也不会投下阴影。我们想要的是在像素处可见的内容,即视图矢量首先与高度场相交的位置。
为了更好地解决这个问题,一些研究人员提出沿着视图矢量使用光线行进,直到找到(近似)交叉点。这项工作可以在像素着色器中完成,其中高度数据可以作为纹理访问。我们将这些方法的研究归结为视差映射技术的子集,这些技术以某种方式利用光线行进。
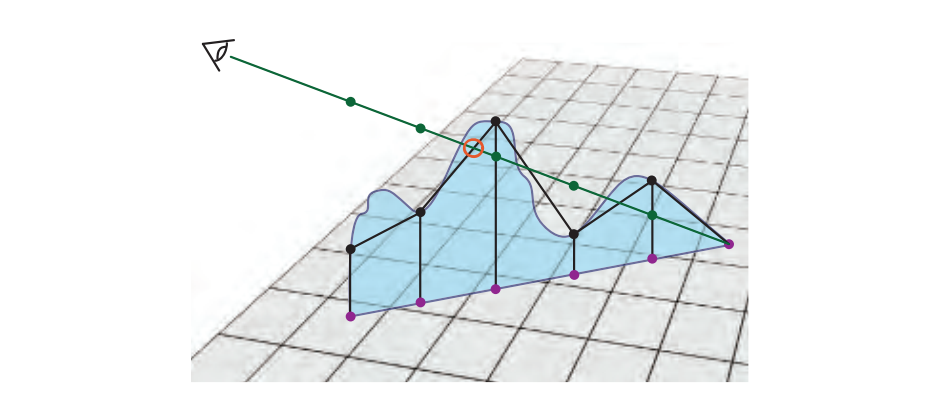
这些类型的算法被称为视差遮挡映射(POM)或浮雕映射(relief mapping)方法,以及其他名称。关键思想是首先沿投影矢量测试固定数量的高度场纹理样本。通常在掠射角处为视图光线生成更多样本,因此不会错过最近的交叉点。检索沿射线的每个三维位置,将其转换为纹理空间,并进行处理以确定其是否高于或低于高度场。一旦找到高度场下方的样本,其下面的量和前一个样本的数量用于查找交叉点位置。然后使用附加的法线贴图,颜色贴图和任何其他纹理,使用该位置对表面进行着色。多层高度场可用于产生悬垂,独立重叠表面和双面浮雕图;见13.7节。高度场追踪方法也可用于使凹凸不平的表面将阴影投射到自身上。有关比较,请参见下图:

(Parallax mapping without ray marching (left) compared to with ray marching (right) )
关于这个主题有很多文献。 虽然所有这些方法沿着光线行进,但存在一些差异。 可以使用简单的纹理来检索高度,但也可以使用更高级的数据结构和更高级的rootfinding方法。 一些技术可能涉及着色器丢弃像素或写入深度缓冲器,这可能损害性能。 下面我们总结一大堆方法,但请记住,随着GPU的发展,最好的方法也是如此。 这个“最佳”方法取决于内容和光线行进期间完成的步骤数。
确定两个常规样本之间的实际交叉点的问题是寻根问题(root-finding problem)。 在实践中,高度场更多地被视为深度场,矩形的平面定义了表面的上限。 这样,平面上的初始点高于高度场。 找到上面的最后一点,并在第一点下面,高度场的表面,Tatarchuk使用割线方法的一个步骤来找到近似解。 Policarpo等。 在两个点之间使用二进制搜索,找到更接近的交叉点。 Risser等通过使用割线方法迭代来加速收敛。 定期采样可以并行完成,而迭代方法需要较少的整体纹理访问,但必须等待结果并执行较慢的相关纹理提取。 简单粗暴的方法似乎总体上表现良好。
频繁地对高度场进行采样至关重要。 McGuire和McGuire建议对mipmap查找进行偏置并使用各向异性mipmap来确保对高频高度场(如表示尖峰或头发的高度场)进行正确采样。 还可以以比法线贴图更高的分辨率存储高度场纹理。 最后,一些渲染系统甚至不存储法线贴图,更喜欢使用交叉滤波器从高度场导出法线。公式16.1显示了该方法。
提高性能和采样精度的另一种方法是不以规则的间隔对高度场进行采样,而是尝试跳过介入的空间。Donnelly将高度场预处理成一组体素,在每个体素中存储距离高度场表面有多远。以这种方式,可以快速跳过居间空间,代价是每个高度场的更高存储量。王等人使用五维位移映射方案来保持从所有方向和位置到地面的距离。这允许复杂的曲面,自阴影和其他效果,代价是相当大的存储量。Mehra和Kumar使用定向距离图进行类似的目的。 Dummer提出,并且Policarpo和Oliveira改进了锥步映射(cone step mapping)的想法。这里的概念是还为每个高度场位置存储锥形半径(cone radius)。该半径定义了光线上的间隔,其中与高度场最多有一个交点。此属性允许沿着光线快速跳过而不会遗漏任何可能的交叉点,但代价是需要依赖纹理读取。另一个缺点是创建锥形步骤图所需的预计算,使得该方法不能用于动态改变高度场。 Schroders和Gulik提出了四叉树浮雕映射(quadtree relief mapping),这是一种在遍历期间跳过卷的分层方法。Tevs等使用“最大mipmap”允许跳过,同时最大限度地降低预计算成本。 Drobot还使用存储在mipmap中的四叉树结构来加速遍历,并提出了一种在不同高度域之间进行混合的方法,其中一种地形类型转换为另一种。

上述所有方法的一个问题是,视线沿着对象的轮廓边缘时显示原始表面的平滑轮廓。见上图。关键是渲染的三角形定义了像素着色器程序应该评估哪些像素,而不是表面实际所在的位置。此外对于曲面,轮廓问题变得更加复杂。 Oliveira和Policarpo描述并开发了一种方法,该方法使用二次轮廓近似技术。Jeschke等人和Dachsbacher等人,都提供了更加通用和强大的方法(并回顾以前的工作),以正确处理轮廓和曲面。首先由Hirche探索,一般的想法是将网格中的每个三角形向外挤出并形成棱镜。渲染此棱镜会强制计算可能出现高度场的所有像素。这种类型的方法称为shell映射,因为展开的网格在原始模型上形成单独的shell。通过在与光线相交时保留棱镜的非线性特性,可以实现高度场的无伪像渲染,尽管计算成本很高。这种技术的令人印象深刻的用途如图:

6.9 Textured Lights(贴图光照)
纹理还可用于为光源添加视觉丰富度,并允许复杂的强度分布或聚光灯功能。对于将所有照明限制在圆锥或平截头体上的光,可以使用投影纹理来调制光强度。这允许形状聚光灯,图案灯,甚至“幻灯片投影仪“效果。这些灯通常被称为图案灯或饼干灯,在专业剧院和电影照明中使用的剪切术语之后。参见第7.2节投影映射的讨论以类似的方式用于投射阴影。
对于不限于平截头体但在所有方向上照明的光,可以使用立方体图来调制强度,而不是二维投影纹理。 一维纹理可用于定义任意距离衰减函数。 结合二维角度衰减图,这可以允许复杂的体积照明模式。 更普遍的可能性是使用三维(体积)纹理来控制光的衰减。 这允许任意体积的效果,包括光束。此技术是内存密集型的(与所有体积纹理一样)。如果光的效果量沿三个轴对称,则通过将数据镜像到每个八分圆中,可以将内存占用减少八倍。
可以将纹理添加到任何灯光类型以启用其他视觉效果。 纹理灯允许艺术家轻松控制照明,艺术家可以简单地编辑所使用的纹理。
Further Reading and Resources
- 赫克伯特已经对纹理映射理论进行了很好的调查,并对该主题进行了更为深入的报道。
- Szirmay-Kalos和Umenhoffer对视差遮挡映射和置换方法进行了很好的全面调查。有关正常表示的更多信息可以在Cigolle等人的着作中找到。
- 使用OpenGL的高级图形编程一书使用纹理算法广泛覆盖了各种可视化技术。有关三维程序纹理的广泛报道,请参阅纹理和建模:程序方法。
- “可编程图形硬件高级游戏开发”一书有很多关于实现视差遮挡映射技术的细节,Tatarchuk的演示和Szirmay-Kalos以及Umenhoffer的调查也是如此。
- 对于程序纹理(和建模),我们在互联网上最喜欢的网站是Shadertoy。 显示屏上有许多有价值且引人入胜的程序纹理功能,您可以轻松修改任何示例并查看结果。
- 访问本书的网站realtimerendering.com,获取许多其他资源。
(chapter 6 end.)